A Quina é uma das loterias tradicionais da Caixa, embora receba menos atenção do que a Mega-Sena. Alguns de seus sorteios entregam prêmios de centenas de milhões de reais. Com um desses sorteios se aproximando, eu quis entender – e discutir por aqui: qual a probabilidade de ganhar na Quina?
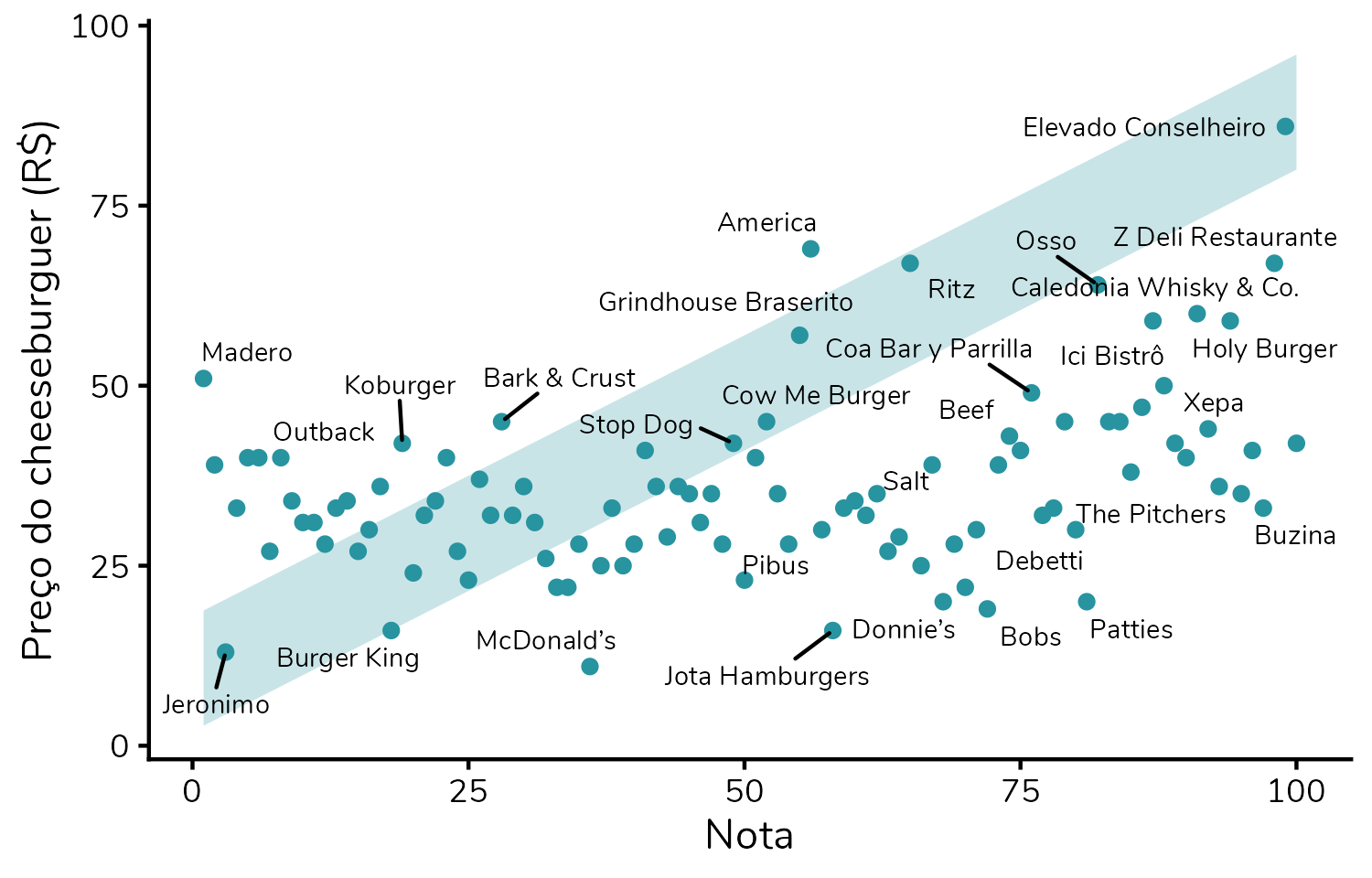
Recentemente, pipocou pela internet um gráfico sobre o custo-benefício de 100 hamburguerias da cidade de São Paulo. E, como tudo na internet em 2025, acabou gerando briga nos comentários. Mas eu, particularmente, achei o gráfico um ótimo ponto de partida para conversarmos sobre princípios de visualização de dados. É exatamente isso que trago neste post.
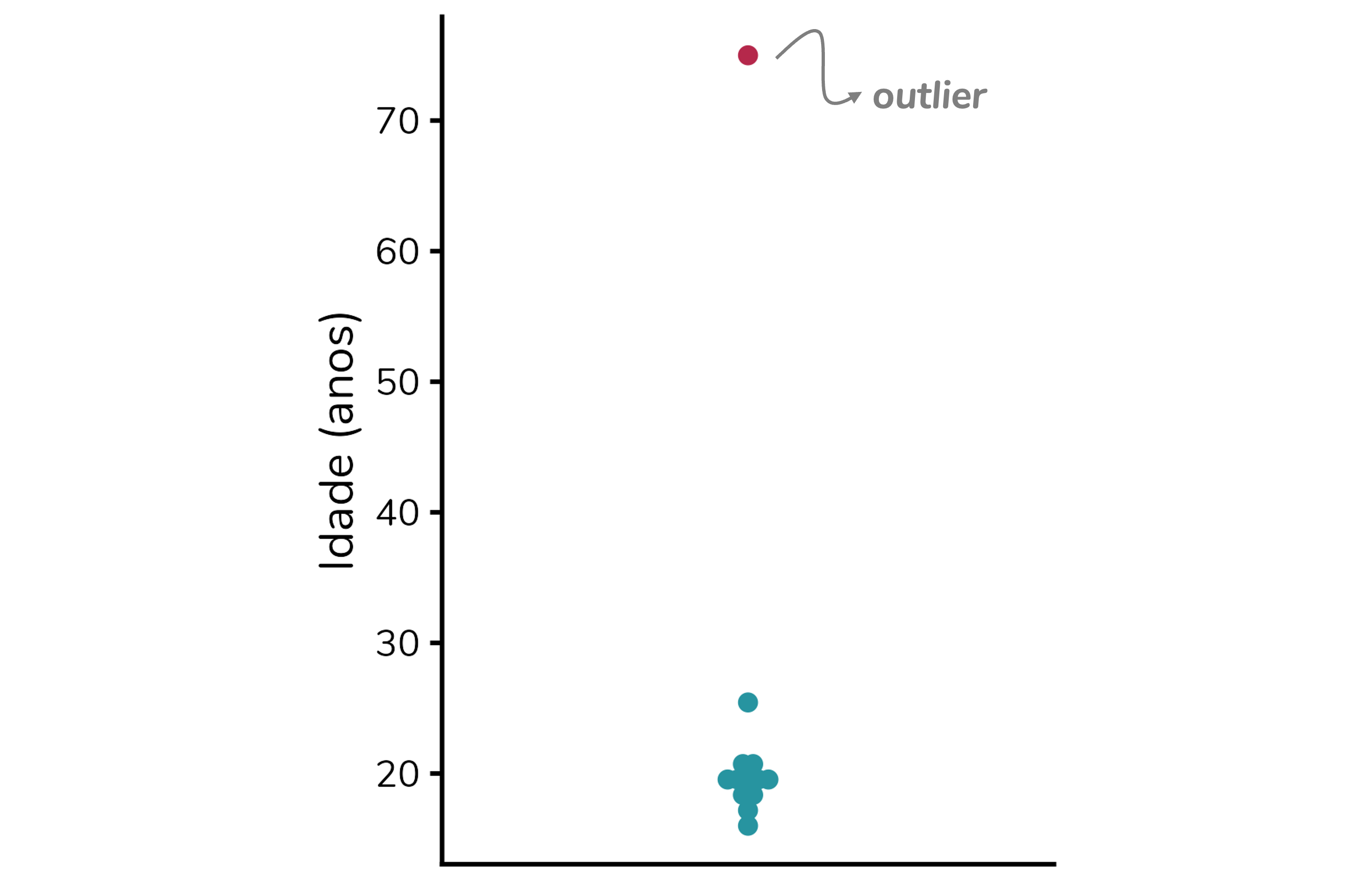
Já ouviu por aí o termo “outlier”, mas ficou sem entender o que ele significa? Nesse post eu discuto o que é e como identificar um outlier. Também te explico como “tratá-los”.
Já se perguntou qual é a probabilidade real de ganhar na Mega-Sena? Neste post, eu explico de onde vem esse número, como a probabilidade muda quando fazemos mais apostas ou apostamos em mais números, e o porquê aumentar a probabilidade de ganhar não significa, necessariamente, sair no lucro.
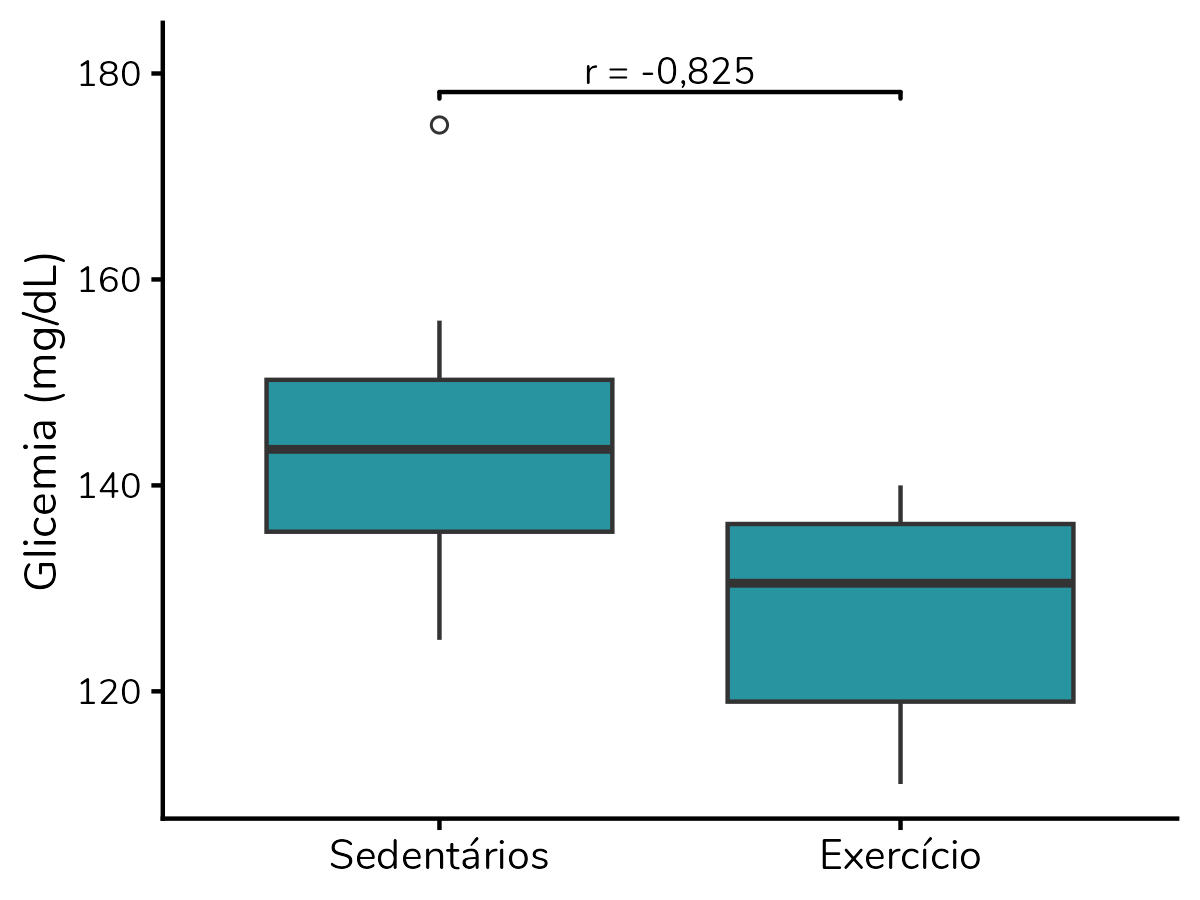
Sabia que há mais de um tamanho de efeito sugerido para o teste não-paramétrico de Mann-Whitney? Neste post te explico os três tamanhos de efeito sugeridos (r, VDA e correlação rank-biserial), como interpretá-los e calculá-los.