Tamanhos de efeito para o teste de Mann-Whitney
Em um post anterior eu te expliquei o que é tamanho de efeito e o porquê você deveria calculá-lo nas suas análises. Nesse post, vamos discutir os tamanhos de efeito adequados a um teste não-paramétrico que compara as distribuições de dois grupos independentes: o teste de Mann-Whitney.
Se você já se aventurou a pesquisar sobre tamanhos de efeito para testes não-paramétricos, deve ter percebido que a literatura sobre esse tema é bem mais escassa e dispersa que a de tamanhos de efeito para testes paramétricos (como testes-t, ANOVAs). Isso me motivou a publicar recentemente um artigo de revisão sobre esse tema (Peres, 2025). Caso o assunto seja do seu interesse, recomendo a leitura! Você pode baixá-lo gratuitamente neste link :)
Este post está dividido nos seguintes tópicos:
- O que é o teste de Mann-Whitney
- Tamanho de efeito r
- Tamanho de efeito VDA (Linguagem comum)
- Tamanho de efeito correlação rank-biserial
- Como citar esse post, nas normas da ABNT
- Referências
O que é o teste de Mann-Whitney
O teste de Mann-Whitney – também conhecido como teste da soma dos postos de Wilcoxon (em inglês, Wilcoxon rank-sum test), ou ainda teste Wilcoxon-Mann-Whitney – compara as distribuições de dois grupos independentes. Portanto, usamos o teste de Mann-Whitney quando temos uma variável independente com duas categorias. Já a variável dependente pode ser de natureza numérica ou ordinal (King; Rosopa; Minium, 2018).
É comum vermos o teste de Mann-Whitney sendo descrito como um teste que compara as medianas de dois grupos independentes. No entanto, essa interpretação é incorreta. O teste de Mann-Whitney compara as distribuições dos dois grupos em análise, de forma que é possível observar diferenças estatisticamente significativas mesmo quando os grupos apresentam medianas idênticas. O teste de Mann-Whitney pode ser interpretado como um teste de comparação de medianas apenas quando os dois grupos em comparação apresentam distribuições com formato e espalhamento muito semelhantes. Para uma discussão mais aprofundada sobre as hipóteses do teste de Mann-Whitney, recomendo a leitura de Hart (2001).
Caso tenha interesse em entender com mais profundidade o cálculo por trás do teste de Mann-Whitney, recomendo esse vídeo do meu canal, que mostra o passo-a-passo do cálculo manual.
Tamanho de efeito r
O tamanho de efeito mais reportado após a realização de um teste de Mann-Whitney é o tamanho de efeito r. Para calcular esse tamanho de efeito precisamos apenas do valor de z e do N. O z corresponde à estatística padronizada do teste de Mann-Whitney, liberada pela maior parte dos softwares de análise estatística, como o SPSS. Já o N é o tamanho total da amostra, considerando os dois grupos (Fritz; Morris; Richler, 2012).
\[ r = \frac{z}{\sqrt{N}} \]
Caso o valor de z não seja liberado pelo software estatístico que você está utilizando, é possível calculá-lo manualmente. No meu artigo você encontra a fórmula e as referências para esse cálculo (Peres, 2025).
Calculando o valor de r
No software R
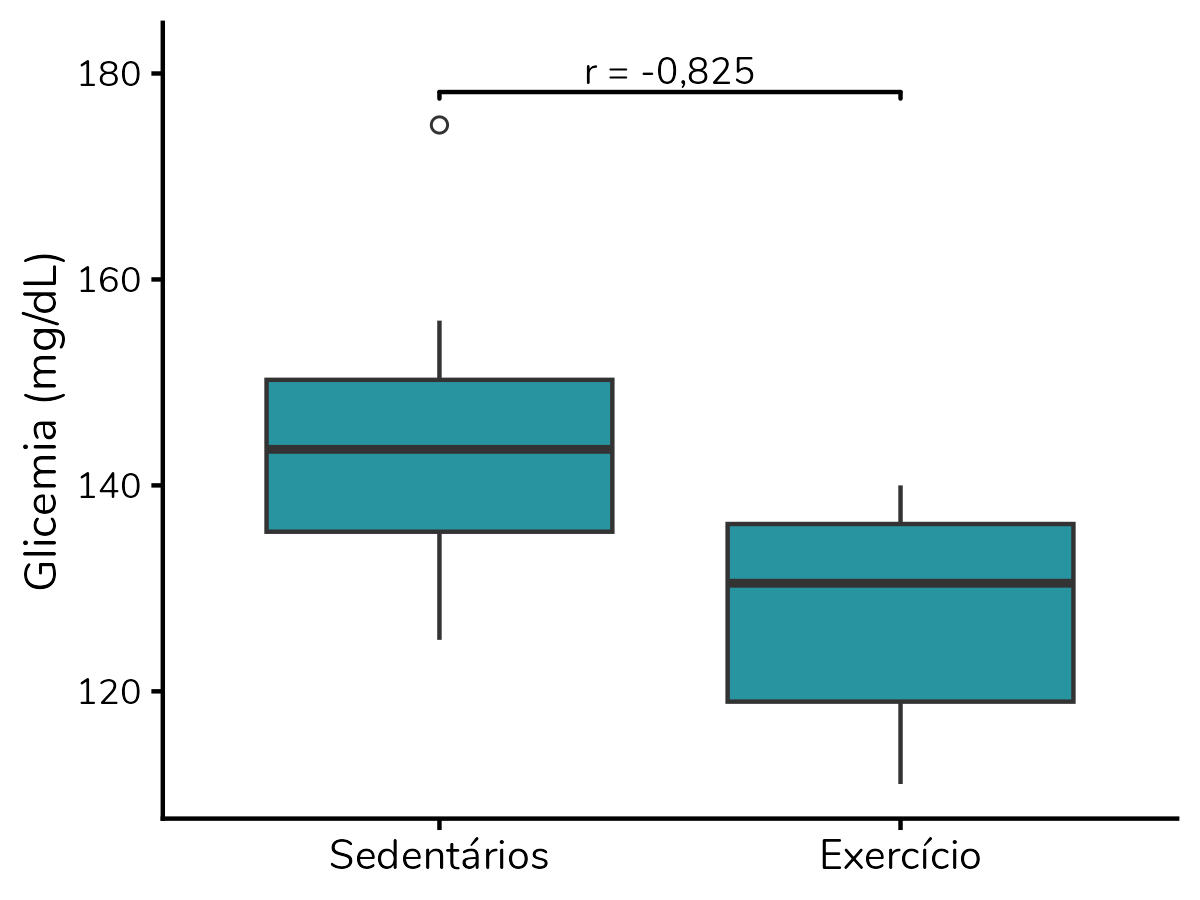
Caso você use o software R (R Core Team, 2025), minha recomendação é calcular o valor de r com a função wilcoxonR() do pacote rcompanion (Mangiafico, 2025). Para tudo fazer mais sentido, vamos partir de uma base de exemplo, com dados de glicemia de dois grupos, um formado por pessoas que praticam exercícios físicos regularmente e outro por sedentários:
# Criação da base de dados
set.seed(4321)
dados <- as.data.frame(list(Grupo = c(rep("Exercício", 29), rep("Sedentários", 31)),
Glicemia = c(round(rnorm(29, mean = 95, sd = 10)),
round(rnorm(31, mean = 120, sd = 15)))))Perceba que os participantes do grupo sedentário tendem a apresentar valores mais altos de glicemia do que aqueles que praticam exercícios regularmente.
Como calcular o tamanho de efeito r para essa base, em R?
# Cálculo do tamanho de efeito r
library(rcompanion)
rcompanion::wilcoxonR(x = dados$Glicemia, g = dados$Grupo)## r
## -0.825Veja que isso resulta em um tamanho de efeito r de -0,825. No próximo tópico vamos discutir como interpretá-lo.
Com uma planilha de Excel
Caso você não use o software R, você pode calcular o tamanho de efeito r em uma planilha de Excel que eu criei. Neste vídeo eu te explico como utilizar a planilha para esse cálculo e, na descrição, você encontra o link para baixá-la. Caso não queira citar o vídeo do YouTube no seu trabalho, você pode citar o meu artigo de 2025, no qual eu disponibilizo uma planilha equivalente (Peres, 2025).
Só um ponto de atenção: caso você use o valor de z calculado pela planilha, há uma diferença entre a planilha do YouTube e a fornecida como material suplementar do artigo. A do YouTube inclui a correção de continuidade (em inglês, continuity correction) e a do artigo usa a primeira fórmula proposta, sem essa correção.
Mas, se você estiver usando o z calculado pelo software, os resultados serão idênticos.
Como interpretar o valor de r?
O valor de r varia de -1 a 1, sendo que o valor zero indica ausência de diferenças entre os dois grupos. Há mais de uma sugestão de classificação para esse valor de r, mas a mais comumente utilizada é (Cohen, 1988; Fritz; Morris; Richler, 2012; Peres, 2025):
- r ≥ 0,1 = efeito pequeno
- r ≥ 0,3 = efeito médio
- r ≥ 0,5 = efeito grande
Ah, essas classificações se referem ao valor absoluto, ignorando o sinal. Portanto, no nosso exemplo, o r = -0,825 seria classificado como um efeito grande.
No entanto, vale destacar que essa ou outras classificações são, de fato, apenas sugestões. É possível que um tamanho de efeito classificado como grande corresponda a uma alteração de magnitude clinicamente irrelevante. Da mesma forma, um tamanho de efeito classificado como irrisório (inferior a pequeno) pode representar uma alteração de magnitude significativa na prática. Portanto, recomenda-se que a interpretação do tamanho de efeito leve em consideração o contexto (Schäfer; Schwarz, 2019; Thompson, 2007). O próprio Cohen enfatiza bastante isso no seu livro (Cohen, 1988).
Tamanho de efeito VDA (Linguagem comum)
Existe um tipo de tamanho de efeito chamado de “linguagem comum”, abreviado como CLES, do inglês Common Language Effect Size. A proposta desse tipo de tamanho de efeito é tornar a informação da magnitude do efeito mais intuitiva, facilitando a sua interpretação. Esses tamanhos de efeito correspondem a probabilidades de superioridade, termo também frequentemente utilizado para descrevê-los.
Para o teste de Mann-Whitney o tamanho de efeito linguagem comum recebe o nome de “A de Vargha e Delaney” (abreviado como VDA, do inglês Vargha and Delaney’s A), uma vez que foi proposto por Vargha; Delaney (2000).
O VDA é calculado a partir da fórmula abaixo, para a qual:
- U = estatística não-padronizada do teste de Mann-Whitney
- n1 = tamanho do grupo 1
- n2 = tamanho do grupo 2
\[ VDA = \dfrac{U}{n_1 \times n_2} \]
Calculando o valor de VDA
O cálculo do VDA é bem simples: basta aplicar a fórmula acima. Mas abaixo te explico duas formas de automatizar esse cálculo: 1) calculando o VDA no software R e 2) calculando o VDA com uma planilha de Excel.
No software R
Caso você use o software R (R Core Team, 2025), você pode calcular o valor de VDA com a função vda() do pacote rcompanion (Mangiafico, 2025). Vamos calculá-lo para a base de dados que criamos acima:
# Cálculo do tamanho de efeito VDA
library(rcompanion)
rcompanion::vda(formula = Glicemia ~ Grupo, data = dados)## VDA
## 0.0195Veja que isso resulta em um VDA de 0,038. No próximo tópico vamos discutir como interpretá-lo.
Com uma planilha de Excel
Caso você não use o software R, você pode calcular o VDA na planilha em Excel que eu disponibilizo neste vídeo. Lembrando que ela é equivalente à planilha disponibilizada no meu artigo (Peres, 2025).
Como interpretar o valor de VDA?
O valor de VDA varia de 0 a 1, sendo que o valor 0,5 indica ausência de diferenças entre os dois grupos. Os autores sugerem que esse valor seja classificado da seguinte forma (Vargha; Delaney, 2000):
- VDA ≥ 0,56 = efeito pequeno
- VDA ≥ 0,64 = efeito médio
- VDA ≥ 0,71 = efeito grande
Mas aqui tem um detalhe importante: caso o VDA calculado seja inferior a 0,5, a interpretação deve ser feita em cima do valor complementar – ou seja, devemos subtrair o VDA de 1.
No nosso exemplo, o VDA foi igual a 0,038. Como esse valor é inferior a 0,5, para interpretá-lo e classificá-lo, vamos subtraí-lo de 1:
1 - 0,038
0,962
Pronto, agora podemos classificar o VDA. Como o valor é superior a 0,71, temos um efeito grande.
Com relação à interpretação, o VDA corresponde a uma probabilidade de superioridade. No nosso exemplo, sabemos que os valores de glicemia do grupo “Sedentários” são mais altos que os valores do grupo “Exercício”. Chegamos a um valor de 0,962. Para pensarmos em porcentagem, basta multiplicar esse valor por 100:
Isso significa que, ao sortearmos uma pessoa do grupo sedentário, há 92,6% de probabilidade de que sua glicemia seja maior do que a de uma pessoa sorteada no grupo exercício (Peres, 2025; Vargha; Delaney, 2000).
Tamanho de efeito correlação rank-biserial
Uma terceira possibilidade de tamanho de efeito é a chamada correlação rank-biserial, que pode ser traduzida livremente como correlação posto-bisserial. Essa correlação é equivalente ao tamanho de efeito chamado de delta de Cliff (em inglês, Cliff’s delta). A correlação rank-biserial tende a ser abreviada como rg, enquanto o delta de Cliff é abreviado pela letra grega delta minúscula, δ (Peres, 2025).
Esse tamanho de efeito corresponde a uma transformação linear do tamanho de efeito VDA:
\[ rg = \delta = 2 \times VDA - 1 \]
Ou, caso você prefira a fórmula que não inclui o VDA, ela passa a ser:
\[ rg = \delta = \dfrac{2 \times U}{n_1 \times n_2}-1 \]
Sendo:
- U = estatística não-padronizada do teste de Mann-Whitney
- n1 = tamanho do grupo 1
- n2 = tamanho do grupo 2
Calculando o valor de rg (= δ)
De novo, para cálcular esse tamanho de efeito basta aplicar a fórmula acima. Mas há duas formas de automatizar esse cálculo: 1) calculando o rg (= δ) no software R e 2) calculando o rg (= δ) com uma planilha de Excel.
No software R
Caso você use o software R (R Core Team, 2025), você pode calcular o valor de rg com a função wilcoxonRG() do pacote rcompanion (Mangiafico, 2025) ou com a função rank_biserial() do pacote effectsize (Ben-Shachar; Lüdecke; Makowski, 2020). Vamos calculá-lo para a base de dados que criamos acima:
# Cálculo do tamanho de efeito rg pelo pacote rcompanion
library(rcompanion)
rcompanion::wilcoxonRG(x = dados$Glicemia, g = dados$Grupo)## rg
## -0.961# Cálculo do tamanho de efeito rg pelo pacote effectsize
library(effectsize)
effectsize::rank_biserial(x = dados$Glicemia, y = dados$Grupo)## r (rank biserial) | 95% CI
## ----------------------------------
## -0.96 | [-0.98, -0.93]Veja que isso resulta em um rg de -0,961. No próximo tópico vamos discutir como interpretá-lo.
Com uma planilha de Excel
Caso você não use o software R, você pode calcular o rg na planilha em Excel que eu disponibilizo neste vídeo. Lembrando que ela é equivalente à planilha disponibilizada no meu artigo (Peres, 2025).
Como interpretar o valor de rg (= δ)?
O tamanho de efeito rg (= δ) é uma transformação linear do VDA: enquanto o VDA varia de 0 a 1, com 0,5 indicando ausência de efeito, o rg varia de -1 a 1, com 0 indicando ausência de efeito. De acordo com Vargha; Delaney (2000) esse tamanho de efeito pode ser classificado, em valor absoluto, como:
- rg ≥ 0,11 = efeito pequeno
- rg ≥ 0,28 = efeito médio
- rg ≥ 0,43 = efeito grande
No nosso exemplo, o rg foi igual a -0,961. Para interpretá-lo, vamos ignorar o sinal. Veja que esse é um tamanho de efeito classificado como grande.
Como citar esse post, nas normas da ABNT
PERES, Fernanda F. Tamanhos de efeito para o teste de Mann-Whitney. Blog Fernanda Peres, São Paulo, 28 dez. 2025. Disponível em: https://fernandafperes.com.br/blog/te-mann-whitney/.
Lembrando que todo o conteúdo que está neste post está incluído também no meu artigo de revisão (Peres, 2025).
comments powered by Disqus