O que um gráfico de custo-benefício de hambúrgueres nos ensina sobre estatística?
No final de novembro de 2025, recebi por DM um post do Instagram que trazia um gráfico sobre o custo-benefício de hamburguerias de São Paulo. Nos comentários, tinha de tudo: acusações de manipulação visual, discordâncias acaloradas sobre as notas atribuídas, insinuações de viés político nas avaliações, e o que mais você imaginar. Eu me abstive de mexer nesse vespeiro, mas o gráfico e a polêmica ao redor dele ficaram na minha cabeça. Então, este é um post para conversarmos sobre visualização de dados e estatística, usando o famigerado gráfico dos hambúrgueres como exemplo.
Antes de tudo, os créditos
O gráfico polêmico foi criado por Wellington Kadooka e publicado em seu perfil no LinkedIn. Por questões de direitos autorais, não irei reproduzi-lo aqui.
Os dados utilizados na construção desse gráfico são o resultado da avaliação de 100 hamburguerias da cidade de São Paulo, realizada por três críticos gastronômicos: @ocritico.antigourmet, @tastebr e @gastronomium. Nesse post você encontra uma explicação da metodologia.
Vale deixar claro desde já: este não é um post para discutir se a avaliação foi justa ou não.
É um post para discutirmos os princípios de visualização de dados.
Quanto mais caro eu pago em um hambúrguer, melhor ele tende a ser?
Essa é a pergunta que norteia a construção do gráfico. E aqui eu quero te convidar a fazer comigo um exercício de imaginação:
Vamos supor que avaliamos 100 hamburguerias e existe, de fato, uma relação entre custo e benefício: hambúrgueres mais caros tendem a ser mais bem avaliados, enquanto hambúrgueres mais baratos recebem notas menores.
Se construíssemos um gráfico de dispersão com o custo (preço do hambúrguer) no eixo x e a avaliação – isto é, o “benefício” percebido – no eixo y, como você esperaria que os pontos desse gráfico se comportassem?
Se você respondeu mentalmente algo como “ah, eu esperaria um padrão com os pontos subindo!”, ótimo: estamos alinhados.
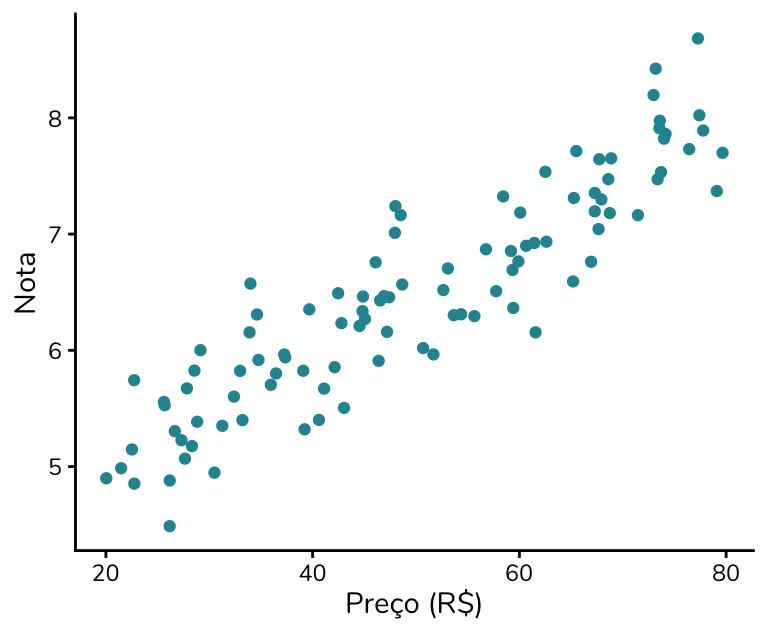
A interpretação desse gráfico é: quanto maior o preço, maior tende a ser a nota recebida pelo hambúrguer. Vale reforçar que os dados apresentados acima são fictícios.
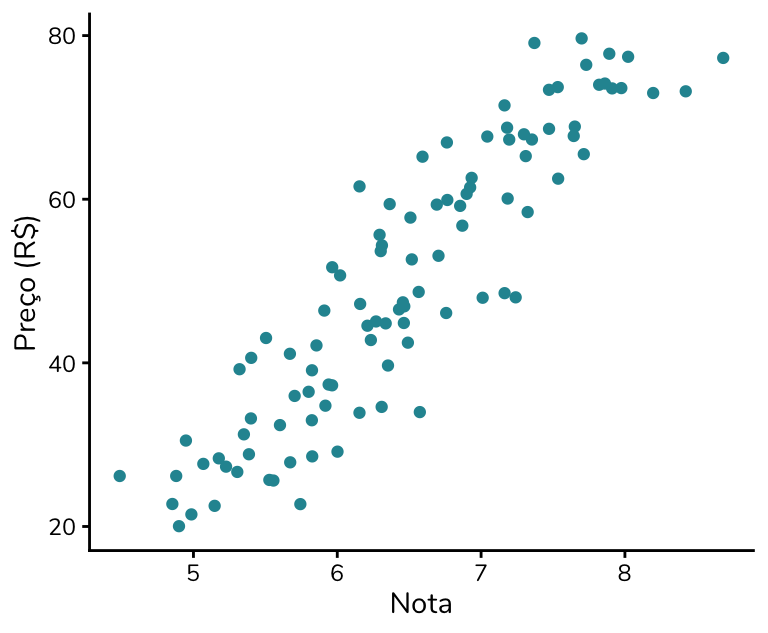
O gráfico que vamos discutir, no entanto, coloca o preço no eixo y e a avaliação no eixo x – o que é um pouco menos intuitivo, mas também válido. Note que, ao invertermos os eixos, continuamos observando um padrão ascendente nos pontos:
Os dados que temos à nossa disposição
O ranking divulgado pelos três perfis (creditados aqui) nos fornece três informações:
- A posição da hamburgueria no ranking
- O preço do cheeseburger
- O preço do cheese-salada
Isso impõe algumas limitações à nossa análise de custo-benefício:
Limitação 1: ranking x nota
Os críticos calcularam uma nota média para cada hamburgueria, mas não temos acesso a ela. Sabemos apenas a posição de cada estabelecimento no ranking. Isso não é o ideal para uma análise de custo-benefício, porque o ranking padroniza artificialmente as distâncias entre as avaliações.
Para essa limitação fazer mais sentido, imagine que temos apenas cinco hamburguerias, que receberam as seguintes avaliações:
Hamburgueria | Nota |
|---|---|
Lanche Feliz | 4,5 |
Tradicional | 4,3 |
Rei dos Lanches | 4,9 |
Esquina | 9,5 |
Pão com ovo | 4,7 |
Se ordenarmos as notas e atribuirmos um ranking a elas, obteremos:
Hamburgueria | Nota | Posição |
|---|---|---|
Esquina | 9,5 | 1 |
Rei dos Lanches | 4,9 | 2 |
Pão com ovo | 4,7 | 3 |
Lanche Feliz | 4,5 | 4 |
Tradicional | 4,3 | 5 |
Perceba que, ao termos acesso apenas ao ranking, somos obrigados a assumir que a diferença de avaliação entre a primeira e a segunda colocadas é a mesma que entre a segunda e a terceira. No entanto, ao observarmos as notas, entendemos que o cenário é completamente diferente: a primeira colocada tem uma avaliação muito superior às demais. A diferença entre a primeira e a segunda colocadas é de 4,6 pontos, enquanto entre a segunda e a terceira é de apenas 0,2 pontos.
Limitação 2: o preço absoluto
O segundo detalhe a considerar é que não sabemos o tamanho dos lanches. Um hambúrguer mais barato pode ser simplesmente menor, o que torna o preço absoluto uma medida inadequada de custo-benefício. Sem padronizar por quantidade (por exemplo, por grama), a comparação entre estabelecimentos fica enviesada.
Eu mesma como com bastante frequência no Patties – que, alerta de spoiler, aparece como um dos melhores custo-benefícios dessa base de dados. Ainda assim, o hambúrguer do Patties é relativamente pequeno: enquanto um hambúrguer do BK é mais do que suficiente para mim, no Patties eu sempre acabo comendo um hambúrguer e meio.
Só deixando claro: isso não é uma crítica ao estabelecimento, mas uma forma de ilustrar como a avaliação baseada apenas no preço absoluto tem as suas limitações.
Vale destacar que essa limitação não é “culpa” dos críticos: o ranking foi criado sem qualquer pretensão de servir como base para uma análise de custo-benefício.
Limitação 3: o delineamento do estudo
Antes de tudo, vale deixar isso muito claro: o que segue aqui não é uma crítica aos avaliadores. Os próprios autores do ranking deixam explícito que têm ciência das limitações do delineamento adotado. E, neste blog, eu sempre reforço: 100% dos estudos têm limitações. O papel delas não é desqualificar um trabalho, mas nos ajudar a interpretar os resultados de forma crítica e honesta.
Dito isso, eis algumas limitações associadas à forma como a avaliação foi executada:
A avaliação de um alimento – ainda que baseada em critérios bem definidos – é inevitavelmente subjetiva. Pessoas diferentes podem chegar a conclusões bastante distintas. Basta ver as discussões inflamadas nos comentários.
Essa variabilidade poderia ser minimizada com um número maior de avaliações independentes. No entanto, aqui temos, na prática, um n = 1. Embora três pessoas tenham participado da avaliação, elas foram juntas aos estabelecimentos, trocaram impressões entre si e divulgaram um ranking único – ou seja, suas opiniões não são independentes.
O delineamento assume que a qualidade de um hambúrguer é estável ao longo do tempo. Na prática, sabemos que isso raramente é verdade: um mesmo lanche pode estar excelente em um dia e decepcionar em outro. O ranking poderia, portanto, ser diferente se a avaliação fosse realizada em outro momento.
Como vários hambúrgueres foram experimentados em um mesmo dia, a avaliação pode ter sido influenciada pela ordem do consumo. Hambúrgueres provados mais cedo podem ter sido mais bem avaliados por terem sido consumidos “de estômago vazio”. Avaliar cada hamburgueria em dias distintos reduziria esse problema, mas tornaria o estudo excessivamente longo e introduziria outros vieses, como alterações no preço pela inflação.
As avaliações não foram cegas: os avaliadores sabiam qual estabelecimento estavam avaliando, o que pode influenciar, ainda que inconscientemente, a percepção do produto.
Vamos, então, construir o gráfico
Leitura da base de dados
O primeiro passo foi extrair manualmente, dos posts no Instagram, o ranking e os preços dos hambúrgueres. Salvei em Excel e ficou com a seguinte estrutura (abaixo uma amostra da listagem):
Listagem |
|---|
11. La Borratxeria (R$ 40 – R$ 46) |
15. Raw Burger (R$ 47 – R$ 57) |
21. Debetti (R$ 30 = R$ 46) |
22. Incêndio (R$ 45) |
23. Pão com Carne (R$ 33 – R$ 36) |
30. Big Kahuna (R$30- 40) |
44. Cabana (R$30 - 40) |
63. Burdog (R$ 33 – R$ 39) |
73. Bark & Crust (R$ 45 – R$ 48) |
79. Backstage Meat & Heat (R$ 34 – R$ 39) |
85: São Carlos Lanches (R$ 30 - R$ 35) |
87: New Dog (R$ 34 - R$ 41) |
92: Dizzy (R$ 34 - R$ 40) |
96: Mania de Churrasco (R$ 40 - R$ 46) |
97: Giraffas (R$ 33 - R$ 33) |
Perceba que não há um padrão perfeito. Às vezes a posição no ranking é seguida por um ponto, às vezes por dois pontos. Para algumas hamburguerias há o preço de dois lanches, para outras, de apenas um. Nem sempre os preços são precedidos por “R$”. Apliquei algumas funções para extrair esses dados em três colunas: Ranking, Preço do cheeseburguer, Preço do cheese-salada.
dados <- readxl::read_excel("Base_hamburgueres.xlsx")
dados <- dados |>
mutate(Ranking = stringr::str_extract(Listagem, "^\\d+"),
Nome = stringr::str_trim(stringr::str_replace_all(stringr::str_extract(stringr::str_replace(Listagem, "^\\d+[.:]\\s*", ""), "^[^\\(]+"), "[\\p{C}]", "")),
Valores = stringr::str_extract_all(Listagem, "R\\$\\s*\\d+"),
Valores = lapply(Valores, \(x) as.numeric(gsub("\\D", "", x))),
Cheeseburguer = sapply(Valores, \(x) if (length(x) > 1) x[1] else x[1]),
`Cheese-salada` = sapply(Valores, \(x) if (length(x) > 1) x[2] else x[1])) |>
select(-c("Valores"))
dados[,c(2,4:5)] <- lapply(dados[,c(2,4:5)], as.numeric)Agora passamos a ter a seguinte base de dados (foram sorteadas apenas algumas linhas):
Listagem | Ranking | Nome | Cheeseburguer | Cheese-salada |
|---|---|---|---|---|
11. La Borratxeria (R$ 40 – R$ 46) | 11 | La Borratxeria | 40 | 46 |
15. Raw Burger (R$ 47 – R$ 57) | 15 | Raw Burger | 47 | 57 |
21. Debetti (R$ 30 = R$ 46) | 21 | Debetti | 30 | 46 |
22. Incêndio (R$ 45) | 22 | Incêndio | 45 | 45 |
23. Pão com Carne (R$ 33 – R$ 36) | 23 | Pão com Carne | 33 | 36 |
30. Big Kahuna (R$30- 40) | 30 | Big Kahuna | 30 | 30 |
44. Cabana (R$30 - 40) | 44 | Cabana | 30 | 30 |
63. Burdog (R$ 33 – R$ 39) | 63 | Burdog | 33 | 39 |
73. Bark & Crust (R$ 45 – R$ 48) | 73 | Bark & Crust | 45 | 48 |
79. Backstage Meat & Heat (R$ 34 – R$ 39) | 79 | Backstage Meat & Heat | 34 | 39 |
85: São Carlos Lanches (R$ 30 - R$ 35) | 85 | São Carlos Lanches | 30 | 35 |
87: New Dog (R$ 34 - R$ 41) | 87 | New Dog | 34 | 41 |
92: Dizzy (R$ 34 - R$ 40) | 92 | Dizzy | 34 | 40 |
96: Mania de Churrasco (R$ 40 - R$ 46) | 96 | Mania de Churrasco | 40 | 46 |
97: Giraffas (R$ 33 - R$ 33) | 97 | Giraffas | 33 | 33 |
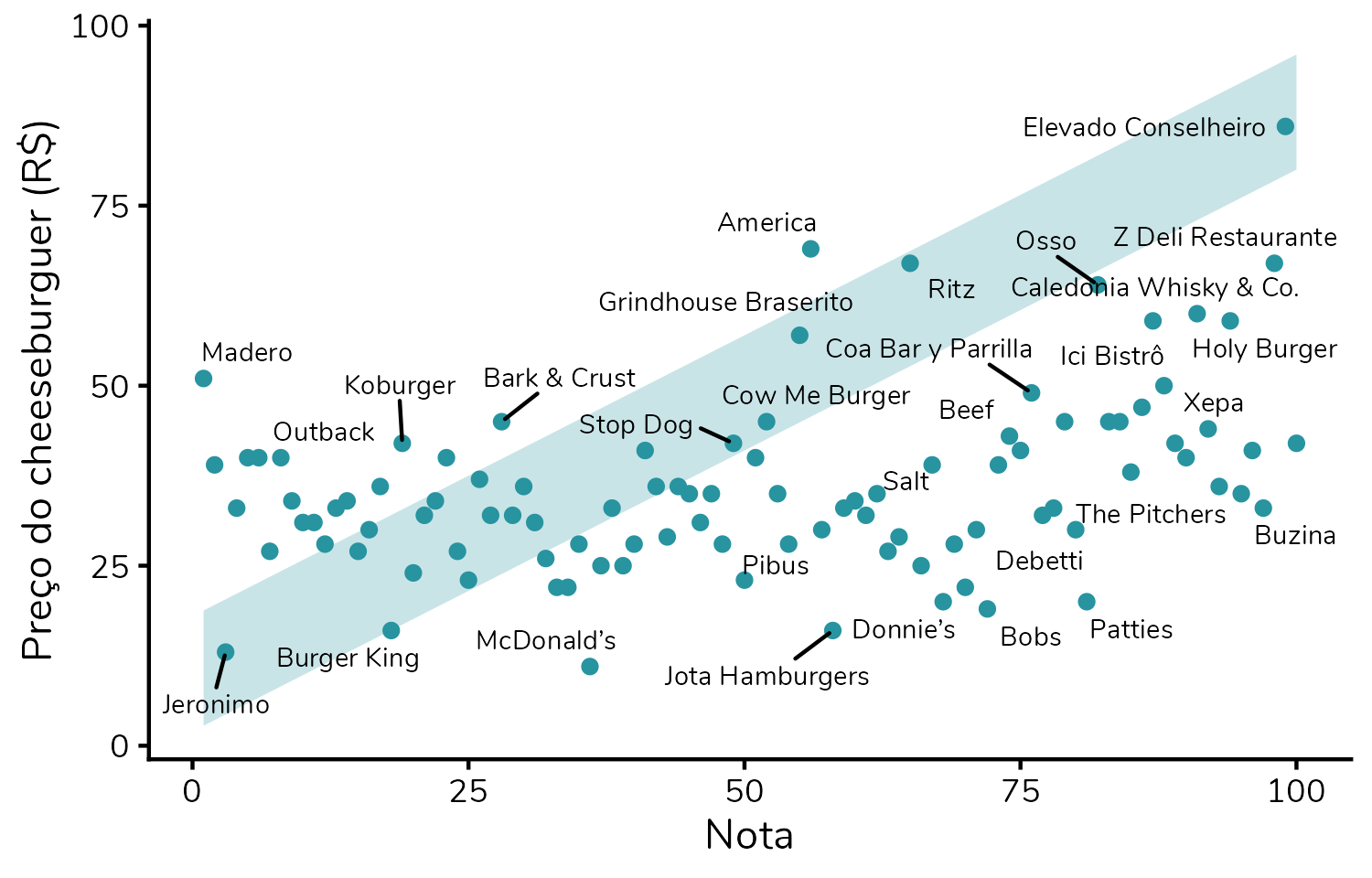
Ótimo! Podemos agora criar um gráfico que relacione o preço do hambúrguer – e aqui vou usar o do cheeseburguer, porque me parece que é o que foi utilizado no gráfico original – à avaliação, mais especificamente ao ranking.
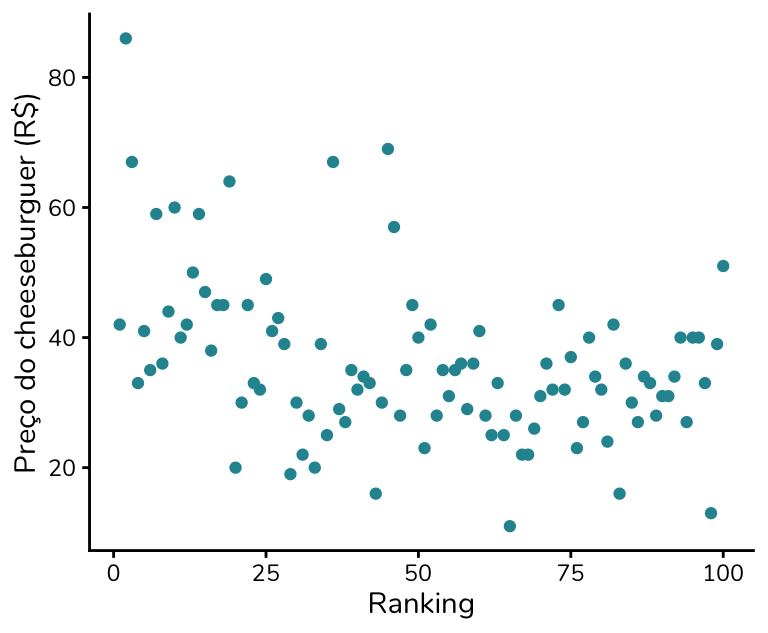
Talvez você tenha olhado para esse gráfico e estranhado: ok, não há um padrão muito claro, mas os pontos parecem “descer”, e não “subir”, como havíamos hipotetizado.
Por que isso acontece? Hambúrgueres mais caros seriam, então, piores?
Essa não é a interpretação correta desse gráfico. Repare que não estamos representando uma nota, mas sim um ranking. Para notas, valores maiores indicam melhor desempenho; já em rankings é o oposto: quanto menor a posição, mais bem avaliado foi o hambúrguer.
É justamente essa inversão que exige um esforço extra de interpretação quando visualizamos um gráfico construído dessa forma.
Qual a alternativa, então?
O autor do gráfico original decidiu inverter o eixo x. Assim, avaliações melhores ficam à direita e as piores à esquerda – reproduzindo a leitura intuitiva que teríamos caso o eixo x trouxesse uma nota, e não um ranking.
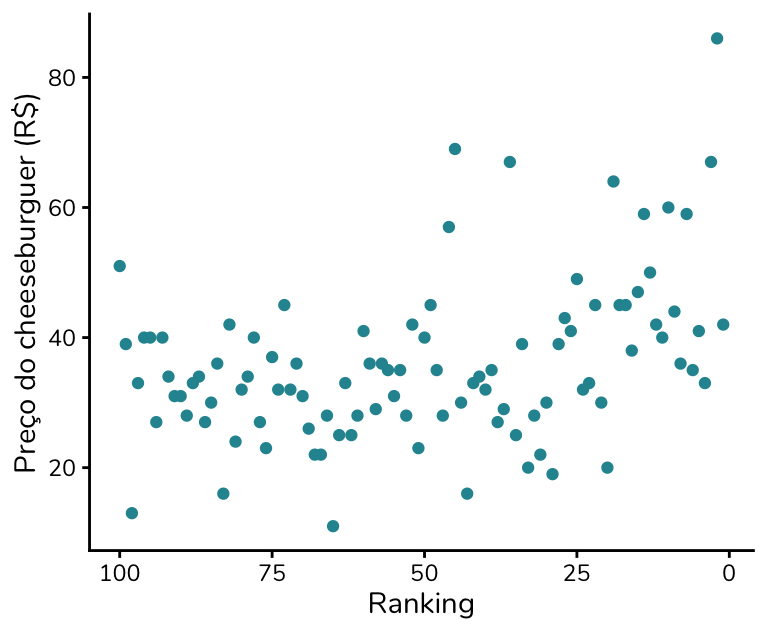
E essa foi a decisão estética que mais gerou polêmica. Muitas pessoas, nos comentários, acusaram o autor do gráfico de ter invertido o eixo x para induzir o leitor ao erro.
Eu, como você já deve ter percebido, discordo dessa acusação. Na minha avaliação, manter o gráfico sem a inversão tem uma probabilidade ainda maior de levar a uma interpretação equivocada.
“Mas, Fernanda, inverter o eixo é um absurdo!”
Olha, pode não ser a melhor estratégia para esse público específico – afinal, um gráfico só pode ser considerado bem construído se for corretamente interpretado pelo público ao qual se destina. E, nesse caso, claramente houve ruído na comunicação.
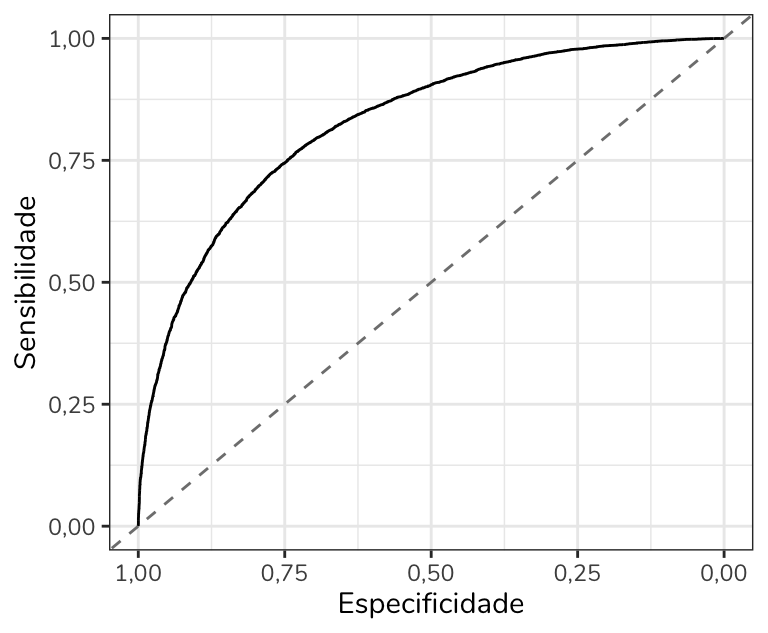
Isso não significa, no entanto, que inverter um eixo seja, por definição, um erro. Em determinados contextos, essa pode ser uma escolha legítima de visualização. Essa é, inclusive, a estratégia adotada em boa parte dos gráficos de curva ROC: o eixo y traz a sensibilidade e o eixo x traz a especificidade, mas com o eixo invertido.
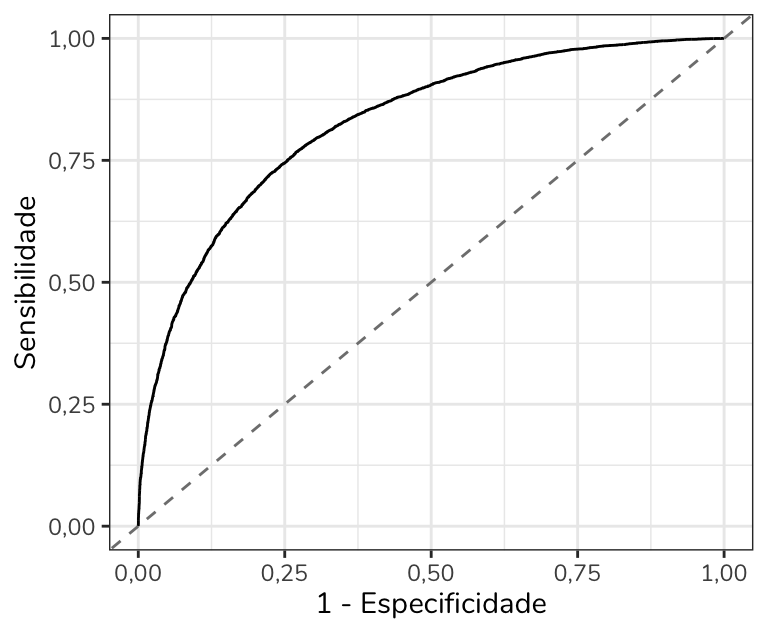
Outra estratégia, bastante comum, utilizada para evitar a inversão do eixo x é construí-lo diretamente com 1 − especificidade. Nesse caso, o gráfico fica visualmente idêntico ao anterior, mas sem a necessidade de inverter a orientação do eixo:
Podemos aplicar essa lógica ao nosso gráfico dos hambúrgueres e construí-lo com 101 - Ranking no eixo x. Assim, não precisamos inverter o eixo. A hamburgueria que ficou em primeiro lugar no ranking passará a ter o valor 100, enquanto a que ficou em último lugar (posição 100) passará a ter o valor 1. Dessa forma, valores “melhores” continuam aparecendo mais à direita do gráfico, o que torna a leitura mais intuitiva.
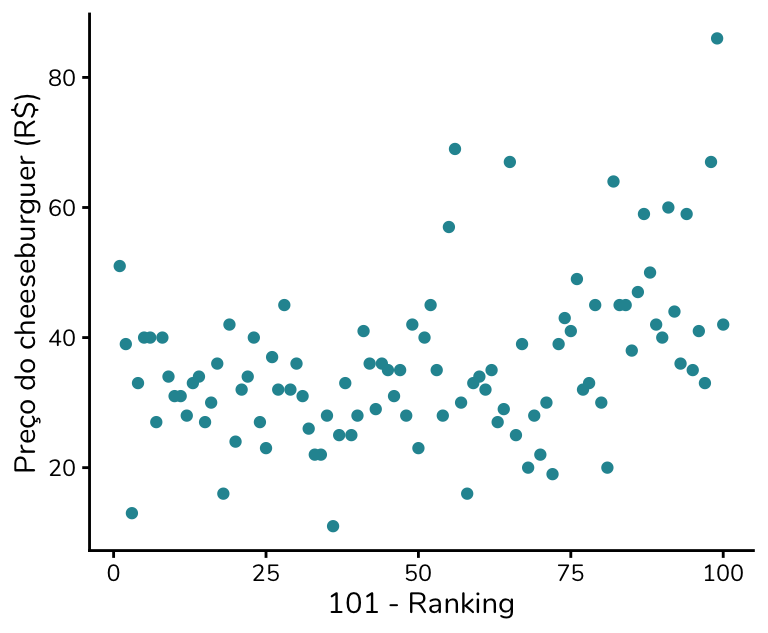
Mas aposto que você está pensando: “continua muito confuso para o leitor!”. Concordo com você. E, aqui, para mim, a solução é renomear o eixo. Em vez de chamá-lo de “101 - Ranking”, podemos chamá-lo simplesmente de “Nota”.
Claro, já sabemos que esse ranking reescalado não é, de fato, uma nota. Mas, como não temos acesso às avaliações originais, essa é a melhor aproximação disponível para representar visualmente a ideia de quão bem avaliado cada estabelecimento foi.
Adicionei também os nomes das hamburguerias aos pontos. Fica um pouco poluído, mas conversaremos sobre isso mais para frente, ok?
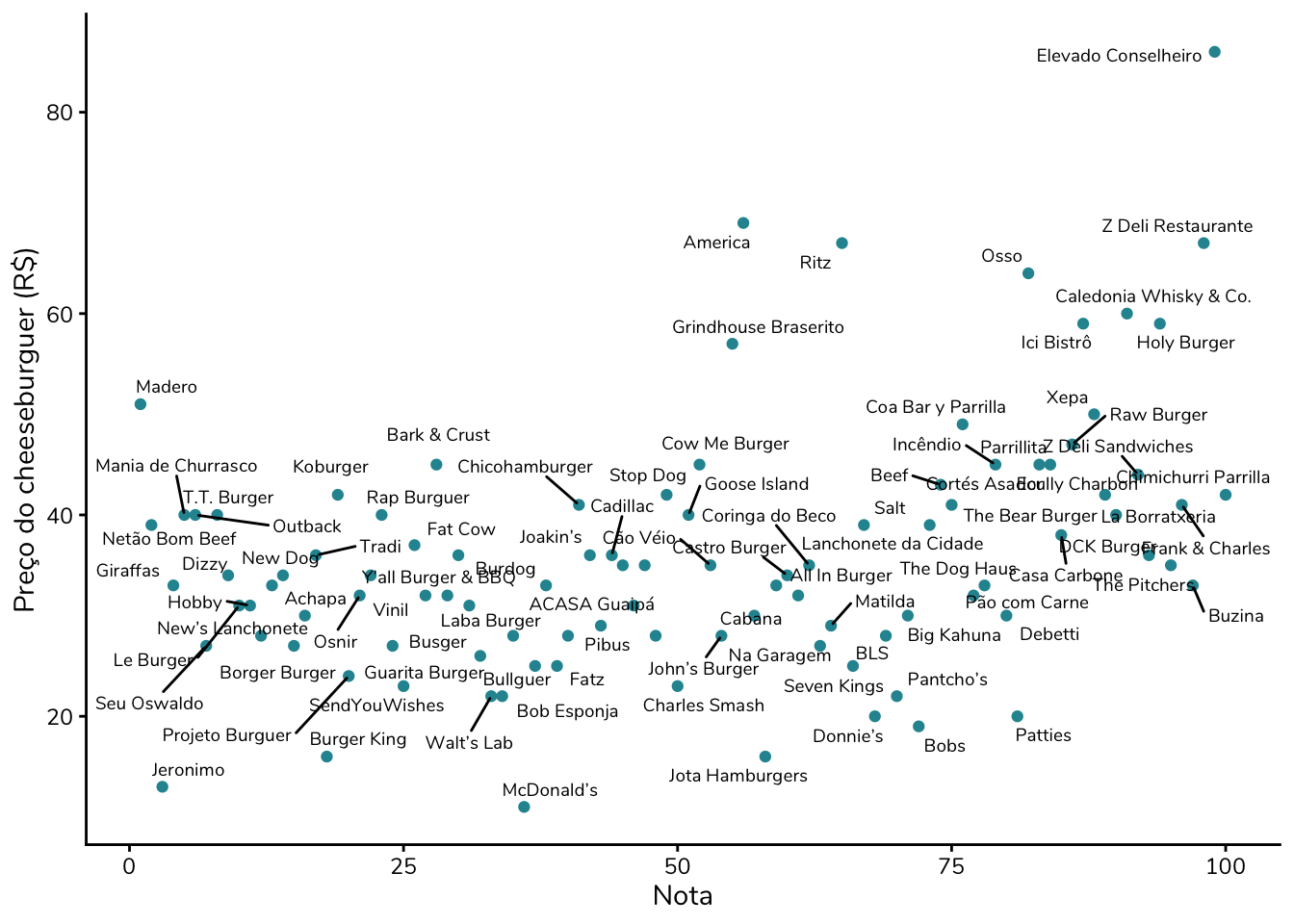
Até aí, tudo bem
Até esse ponto, eu concordo com as decisões do autor do gráfico. Não considero um erro, por si só, inverter o eixo – ainda que, para o público geral, essa escolha claramente não tenha funcionado. A opção por um gráfico de dispersão também me parece adequada.
O problema surge quando o autor adiciona uma faixa diagonal que, segundo a legenda, corresponderia à chamada “zona de equivalência de valor”, definida como a região “onde o preço é coerente com o valor entregue”.
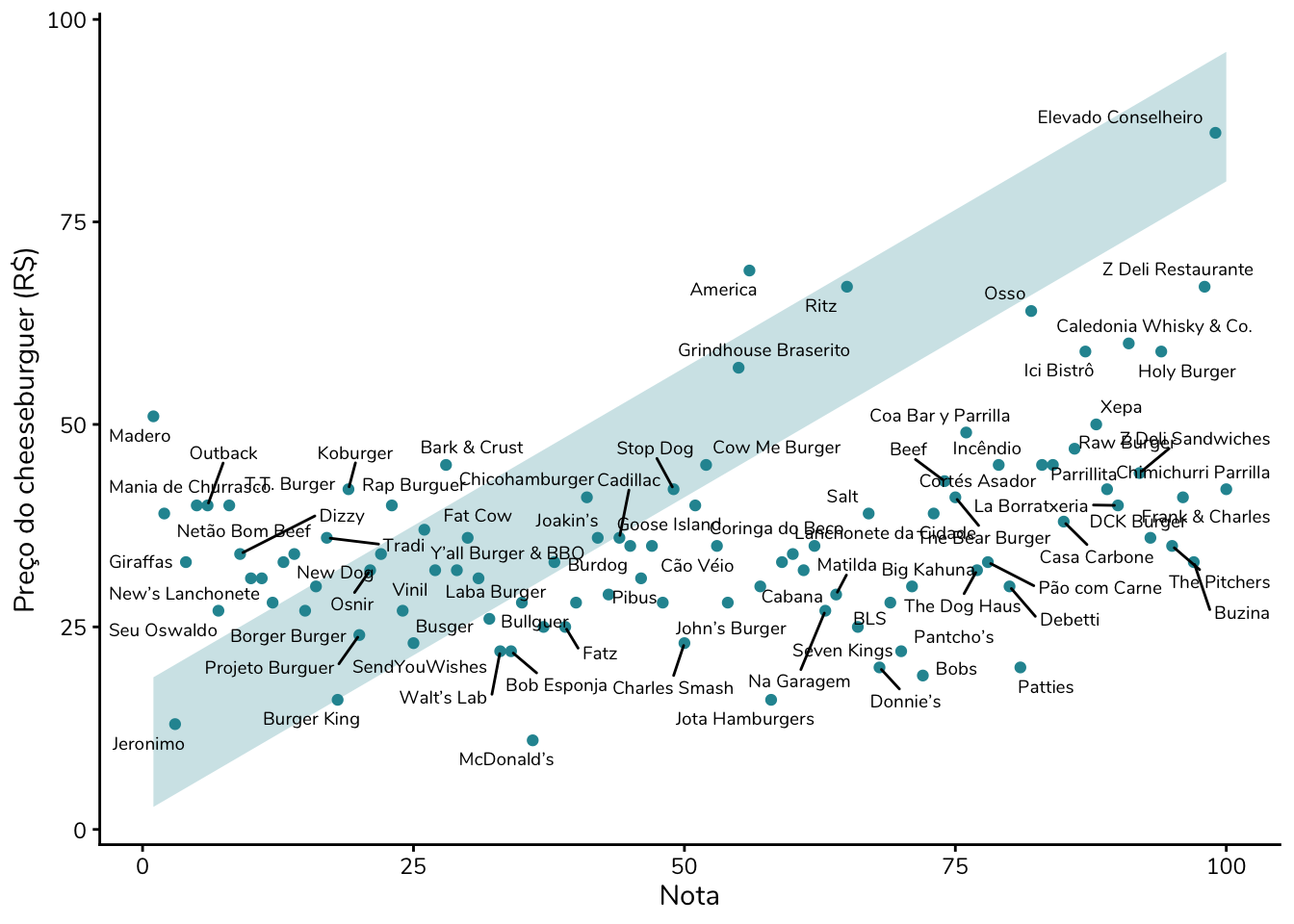
A ideia por trás dessa faixa é simples: hamburguerias dentro dela teriam um custo equivalente ao benefício. As que aparecem acima da faixa apresentariam um custo superior ao benefício, enquanto as que estão abaixo ofereceriam um benefício superior ao custo.
Parece ótimo, certo?
O problema é que não sabemos qual critério foi utilizado para definir essa faixa.
Testei algumas possibilidades, como uma reta de 45°, mas nenhuma delas reproduz o resultado do gráfico original. Depois de algumas tentativas, concluí de que a reta central parece ter sido traçada ligando o ponto mais inferior à esquerda ao ponto mais superior à direita do gráfico.
Esse, infelizmente, não é um bom critério, porque torna a faixa extremamente sensível a valores extremos (outliers): bastaria a presença (ou ausência) de um único ponto muito caro ou muito barato para alterar de forma substancial a inclinação da reta e, consequentemente, a classificação de todas as demais hamburguerias.
Mas como criar uma faixa de equivalência, então?
Antes de mais nada, precisamos avaliar criticamente quais informações temos à nossa disposição. No nosso caso, temos acesso ao preço do cheeseburguer, em reais, e a uma nota, expressa em uma escala de 1 a 100.
O ponto central é que essas duas variáveis estão em unidades de medida diferentes: uma está em reais, a outra em pontuação. Por esse motivo, não faz sentido considerar que a equivalência entre custo e benefício será descrita por uma reta de 45°.
Para entender isso melhor, vamos imaginar um cenário alternativo:
Suponha que, em vez de atribuírem notas ou posições em um ranking, os avaliadores estimassem quanto consideram justo pagar por cada cheeseburguer, também em reais.
Imagine, por exemplo, duas hamburguerias:
- A Hamburgueria “Lanche Feliz” cobra R$ 30 por um cheeseburguer, e os avaliadores consideram que ele “vale” exatamente R$ 30.
- A Hamburgueria “Pão com ovo” cobra R$ 40, mas os avaliadores consideram que o lanche vale apenas R$ 32.
Nesse cenário, tanto o preço quanto o benefício estão na mesma unidade de medida: reais. Um gráfico de dispersão com essas duas variáveis permitiria traçar uma reta de 45°, correspondente à situação em que preço = valor percebido. Pontos acima da reta indicariam um preço maior do que o valor percebido; pontos abaixo, um benefício superior ao custo.
O problema é que esse não é o cenário que temos. No gráfico dos hambúrgueres, custo e benefício estão em unidades de medida diferentes. Para que seja possível traçar uma reta de equivalência, precisamos primeiro tornar essas variáveis comparáveis. Uma estratégia estatística que faz sentido aqui é o cálculo do escore-z, que vai padronizar essas variáveis, tornando-as adimensionais – isto é, sem unidade de medida.
Como calculamos um escore-z?
Para calcular um escore-z, subtraímos de cada valor a média da amostra e dividimos esse resultado pelo desvio-padrão. Esse procedimento faz com que a variável passe a ter média igual a zero e desvio-padrão igual a 1.
Além disso, como a média e o desvio-padrão estão na mesma unidade de medida da variável original, ao realizarmos essa divisão obtemos um valor adimensional, isto é, sem unidade de medida.
Vamos a um exemplo concreto. Para o preço do cheeseburguer, a média da amostra é R$ 35,99 e o desvio-padrão é R$ 12,49. Um lanche cujo preço seja igual à média – aproximadamente R$ 36 – terá, portanto, um escore-z igual a zero.
Já um hambúrguer que custe cerca de R$ 49,50, ou seja, aproximadamente um desvio-padrão acima da média, terá um escore-z igual a 1. Da mesma forma, um cheeseburguer com preço em torno de R$ 24,50, um desvio-padrão abaixo da média, terá escore-z igual a -1.
A tabela abaixo apresenta alguns dos escores-z calculados para os preços. Note que o cheeseburguer mais barato da amostra, o do McDonald’s, possui escore-z igual a -2, indicando que seu preço está dois desvios-padrão abaixo da média. Já o cheeseburguer mais caro apresenta escore-z igual a 4, o que significa que seu preço está quatro desvios-padrão acima da média.
Nome | Ranking | Nota | Cheeseburguer | Escore-z |
|---|---|---|---|---|
McDonald’s | 65 | 36 | 11 | -2,00 |
Charles Smash | 51 | 50 | 23 | -1,04 |
Tradi | 84 | 17 | 36 | 0,00 |
Coa Bar y Parrilla | 25 | 76 | 49 | 1,04 |
Elevado Conselheiro | 2 | 99 | 86 | 4,00 |
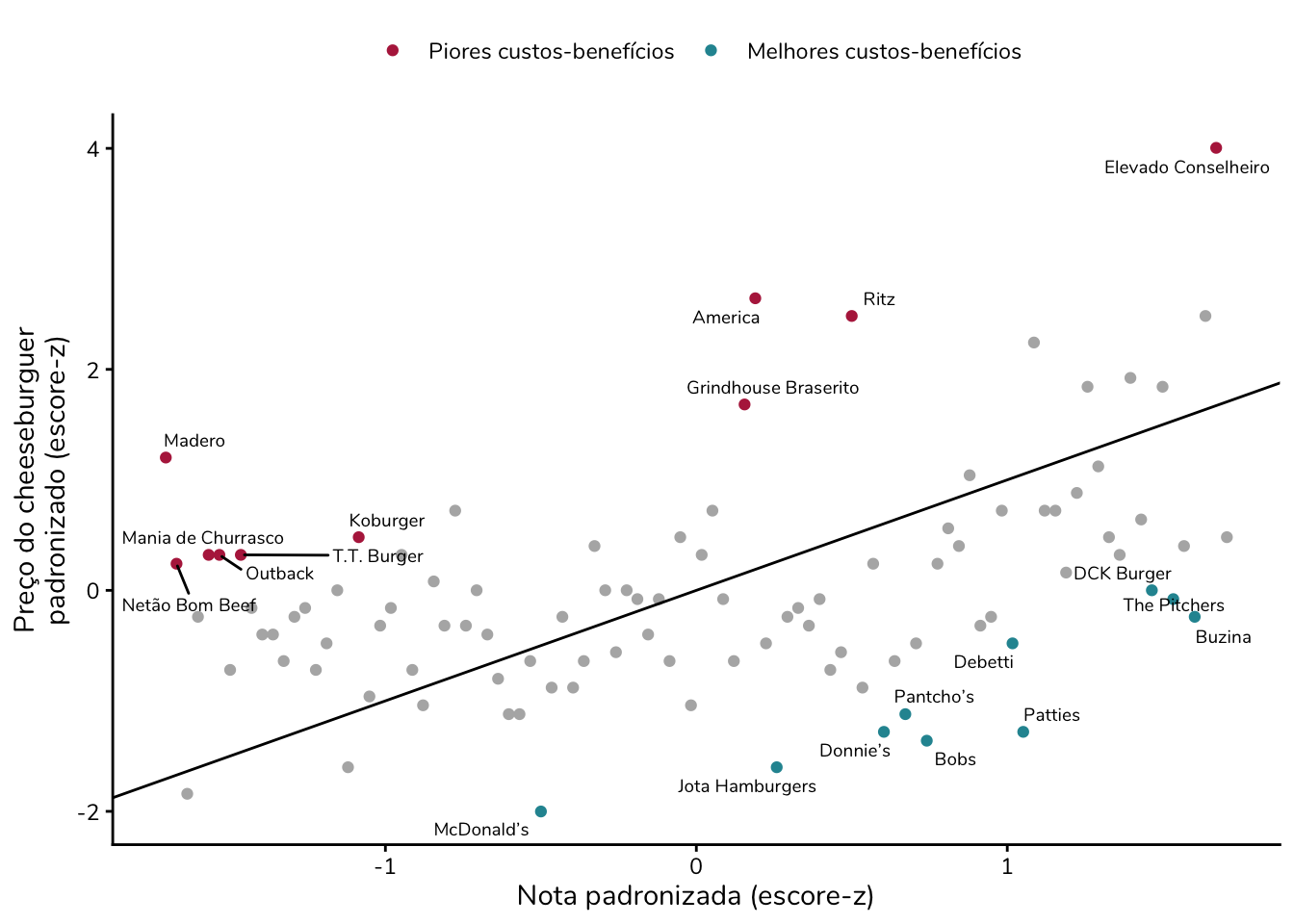
Para criar uma faixa de equivalência, vamos padronizar – isto é, calcular o escore-z – tanto para o preço quanto para a nota. Após essa transformação, poderemos traçar uma reta de 45º.
Essa reta representa situações em que custo e benefício ocupam a mesma posição relativa dentro de suas respectivas distribuições. Como assim?
Em termos práticos, essa reta funciona como uma régua de comparação. Ela passa pelo ponto em que o preço está exatamente na média e a nota também está exatamente na média. A partir daí, ela sobe ligando situações equivalentes: um lanche que está um desvio-padrão acima da média em preço com um lanche que está um desvio-padrão acima da média em nota; dois desvios-padrão acima em preço com dois desvios-padrão acima em nota, e assim sucessivamente.
Repare como essa nova reta difere bastante daquela obtida ao ligar os pontos mais extremos do gráfico. Isso acontece porque, agora, ela não é fortemente influenciada por valores outliers.
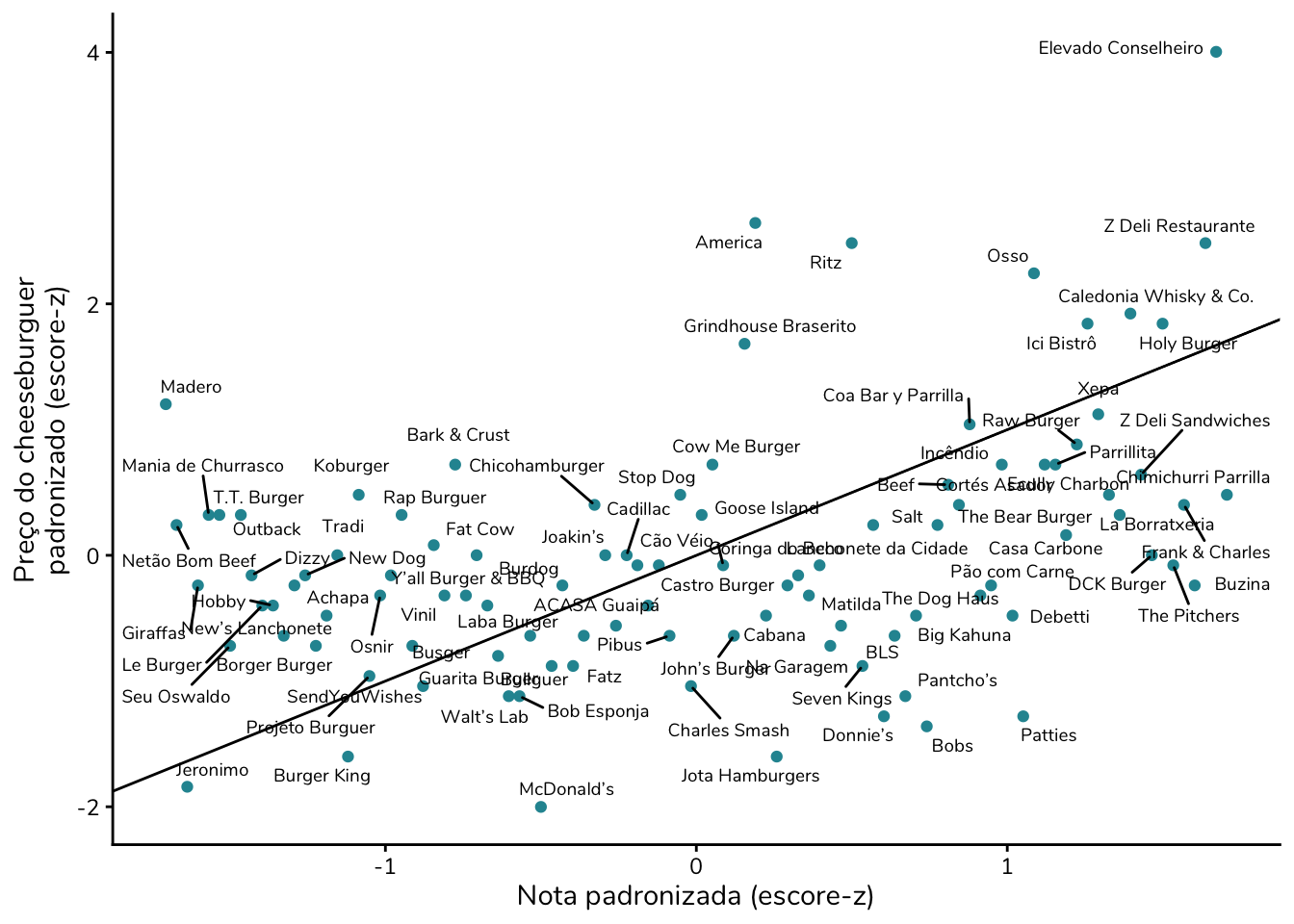
Também podemos usar os escores-z para identificar os pontos com maior diferença relativa entre custo (preço) e benefício (nota). Para isso, basta subtrair o escore-z da nota do escore-z do preço. Essa diferença é apresentada na tabela abaixo como “Relação Custo–Benefício”.
Nome | Nota | Cheeseburguer | Nota padronizada | Preço padronizado | Relação Custo-Benefício |
|---|---|---|---|---|---|
Tradi | 17 | 36 | -1,15 | 0,00 | 1,15 |
McDonald’s | 36 | 11 | -0,50 | -2,00 | -1,50 |
Charles Smash | 50 | 23 | -0,02 | -1,04 | -1,02 |
Coa Bar y Parrilla | 76 | 49 | 0,88 | 1,04 | 0,16 |
Elevado Conselheiro | 99 | 86 | 1,67 | 4,00 | 2,33 |
Essa relação pode ser utilizada para destacar as 10 hamburguerias com melhor custo-benefício e as 10 com pior custo-benefício:
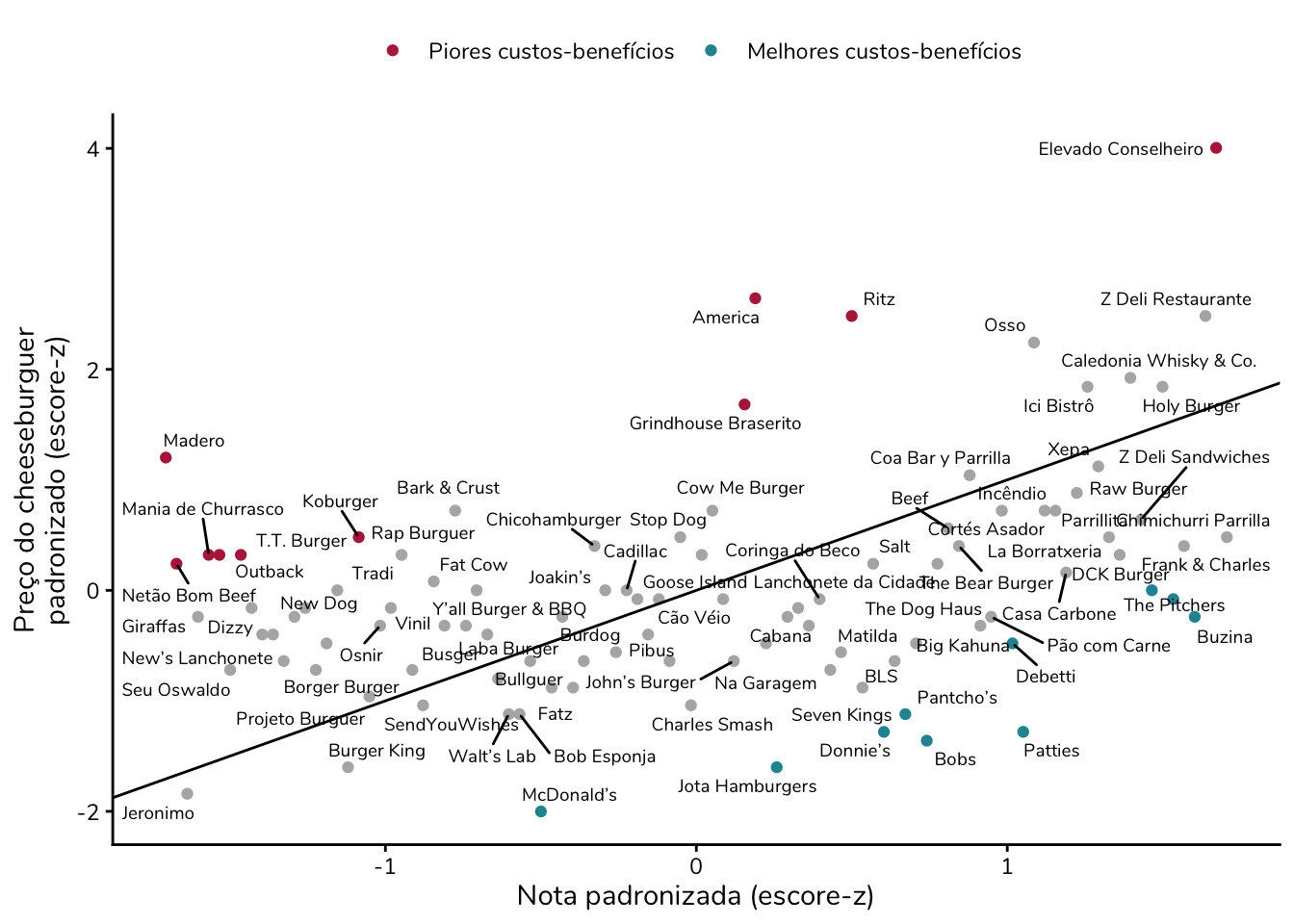
Claro, esse não é o único critério possível. Mas, diante das informações disponíveis, ele é um dos que fazem mais sentido do ponto de vista estatístico.
E vale reforçar: essa análise tem limitações – como qualquer análise de dados –, as quais já discutimos ao longo do texto. O objetivo aqui não é dar uma resposta definitiva, mas olhar para esses dados de uma forma mais criteriosa e transparente.
Em gráficos, menos é mais
No gráfico original, o autor optou por colorir os pontos de acordo com a categoria da hamburgueria: tradicional, fast-food ou restaurante. A ideia é boa, mas, na minha opinião, resultou em informação demais para uma única figura.
Esse tipo de codificação por cor faria mais sentido se o objetivo fosse destacar uma única categoria e discuti-la quanto a relação de custo-benefício. Caso contrário, o excesso de elementos visuais acaba competindo pela atenção do leitor. Como a Cole Knaflic discute no Storytelling com Dados: em visualização, menos é mais.
Para reduzir essa carga visual, optei por destacar apenas os estabelecimentos com os maiores e os menores custos-benefícios, deixando os demais pontos em segundo plano.
Outro fator que contribui para a poluição visual é a tentativa de exibir os nomes das 100 hamburguerias em uma única figura. Inclusive, no gráfico original, alguns nomes acabam não aparecendo, o que rendeu comentários indignados como: “se a Pão com Carne não foi avaliada, não tem como levar esse ranking a sério!”.
O ponto aqui é que a “Pão com Carne” foi, sim, avaliada. O nome simplesmente não aparece porque, com tantos pontos próximos entre si, ocorre sobreposição – e o software utilizado para gerar o gráfico opta por omitir alguns rótulos.
Como resolver esse problema?
Isso vai depender do nosso objetivo. Se o propósito do gráfico for destacar os melhores e piores custos-benefícios, faz sentido nomear apenas as hamburguerias que se encontram nesses extremos:
Por outro lado, se o objetivo for permitir que o leitor explore os preços e as avaliações de todas as hamburguerias, então uma boa solução é transformar o gráfico em uma figura interativa. Nesse caso, ao passar o mouse sobre cada ponto, é possível acessar o nome da hamburgueria, sua posição no ranking e o preço do cheeseburguer:
Como citar esse post, nas normas da ABNT
PERES, Fernanda F. O que um gráfico de custo-benefício de hambúrgueres nos ensina sobre estatística?. Blog Fernanda Peres, São Paulo, 26 jan. 2026. Disponível em: https://fernandafperes.com.br/blog/grafico-hamburgueres/.
comments powered by Disqus