Como representar dados em escala Likert?
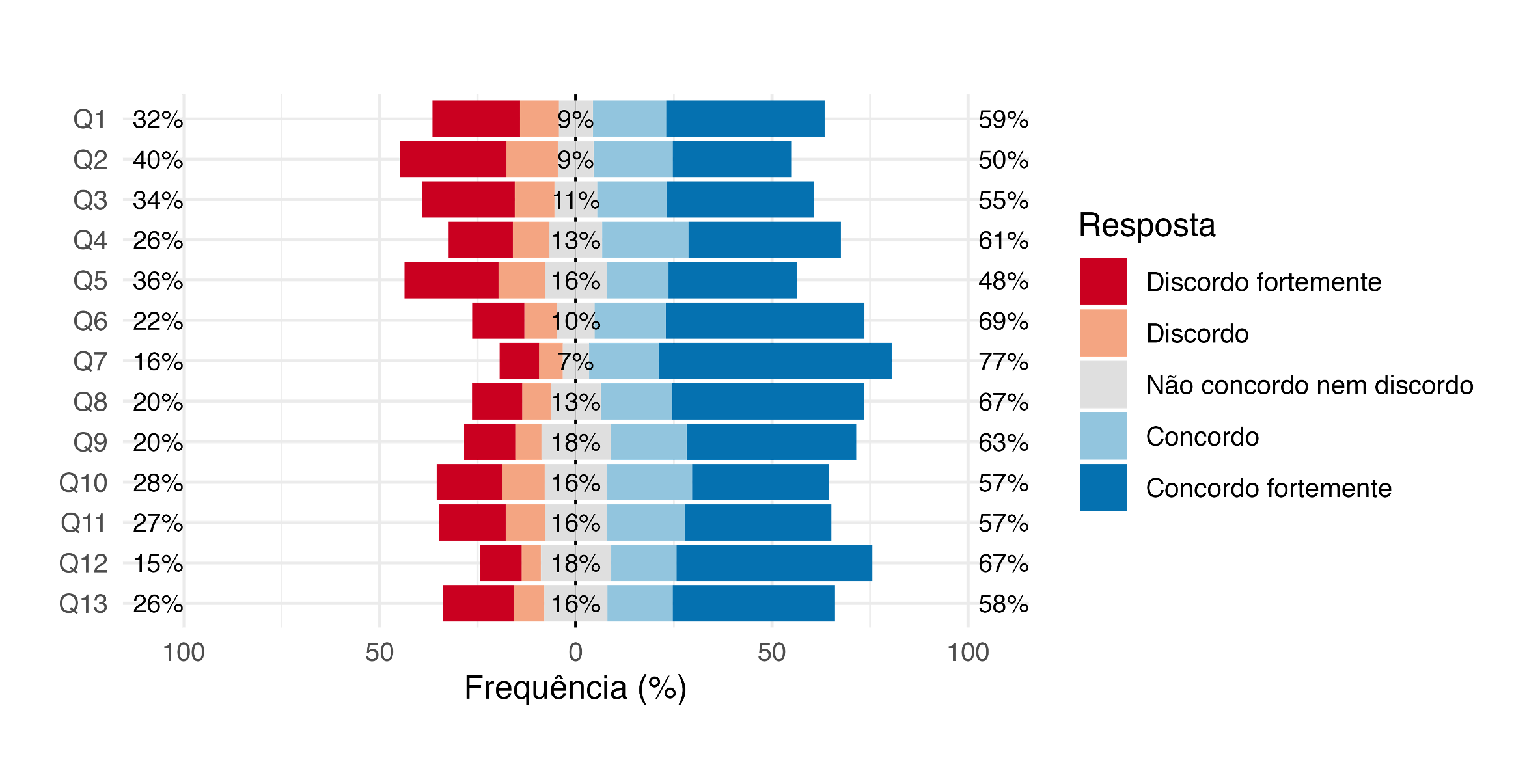
O grande objetivo desse post é te ensinar a interpretar e a criar um gráfico de barras divergentes, como o que você vê acima, adequado à representação de itens Likert. Mas, conforme eu fui estruturando esse post, eu percebi que não tinha como fugir totalmente de algumas questões que geram uma grande crise existencial. O que, afinal, é uma escala Likert? O que diferencia uma escala Likert de um item Likert? Ou ainda, o que os diferencia da escala ou item tipo-Likert?
Por isso, esse post está dividido nos seguintes tópicos:
- O que, afinal, é uma escala Likert?
- Como representar os resultados de itens Likert (ou tipo-Likert ou EVAD)?
- Tá, mas como eu construo esse gráfico?
- Referências
Você pode pular para os tópicos de interpretação e criação do gráfico, se assim desejar, ok?
O que, afinal, é uma escala Likert?
A origem da escala Likert é um artigo de 1932 chamado “A Technique for the Measurement of Attitudes” (em tradução literal: “Uma técnica para medir atitudes”), escrito por Rensis Likert (Likert, 1932). Sim, a escala recebe o nome do autor que a propôs. E uma informação interessante: a palavra Likert deve ser lida como leríamos em português, “Li-quer-ti”, e não como “Lai-quer-ti”. Mas esse é um detalhe.
Como o nome do artigo nos indica, Rensis Likert queria medir atitudes. Após múltiplas tentativas ele chegou a um questionário composto por múltiplos itens (questões) cujas respostas poderiam ser:

Para isso fazer mais sentido, imaginemos alguns itens que podem compor um questionário para avaliar a opinião de funcionários sobre a empresa em que trabalham:
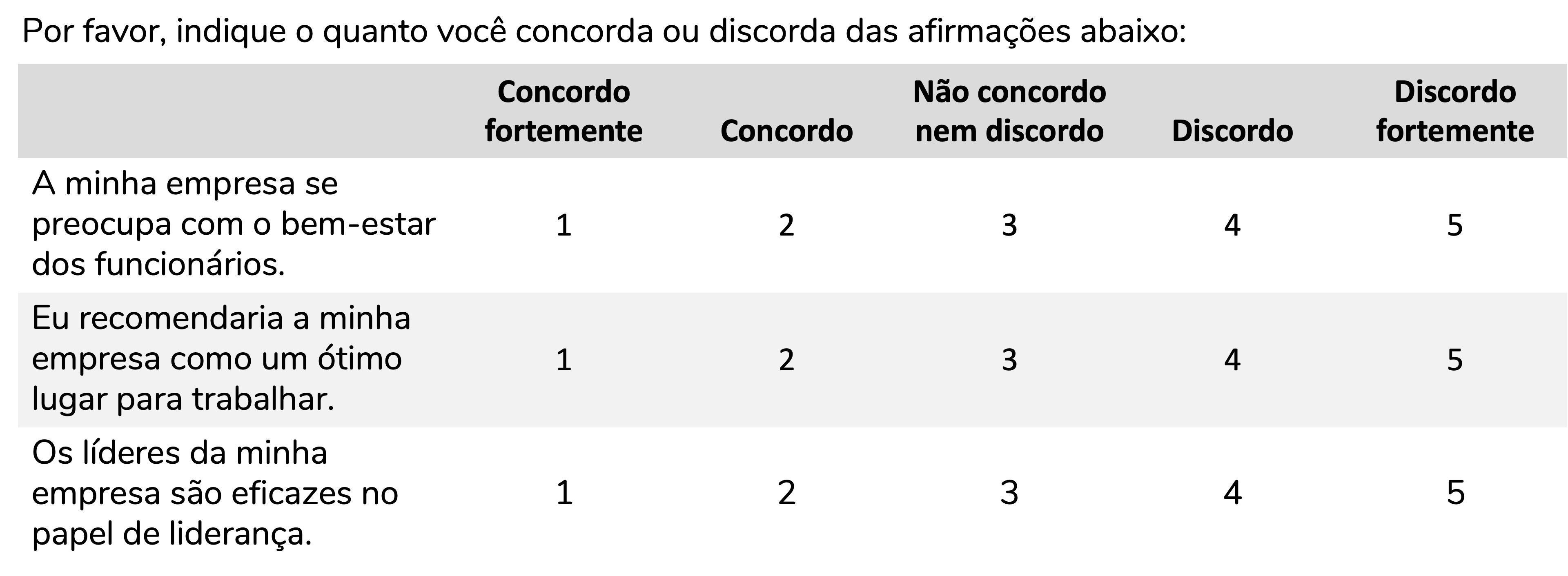
Likert propôs uma escala que seria composta pela soma de múltiplos itens (questões, afirmações) que estivessem relacionados, aferindo um mesmo constructo. Um constructo é uma variável não-observável, que não conseguimos medir diretamente. É o caso de depressão, inteligência ou mesmo atitude.
Escala Likert x item Likert
Para aprofundarmos a nossa discussão, é importante diferenciarmos “escala” de “item”. O item (em inglês, Likert item) é a questão, a afirmação a ser avaliada ou ainda a resposta a essa afirmação. A escala (em inglês, Likert scale) é a soma (ou média) de todos os itens que compõem aquele constructo. Essa é a definição correta. Mas é comum encontrarmos materiais com o termo “escala” sendo utilizado para se referir a um item, o que gera um ruído de comunicação.
Que tipo de variável é uma escala Likert?
Essa é uma das perguntas mais controversas da literatura no que diz respeito a escala Likert. Mas aqui eu tendo a concordar com Batterton; Hale (2017) (e muitos outros): depende.
Se estamos falando do item Likert, como a resposta a essa afirmação abaixo, estamos falando de uma variável categórica ordinal. Perceba que ainda que a resposta seja representada por número de 1 a 5, não se trata de uma variável quantitativa. Não podemos afirmar que a distância entre “Concordo fortemente” e “Não concordo nem discordo” é exatamente a mesma que entre “Concordo” e “Discordo”. O que podemos afirmar é que quanto maior o valor atribuído, maior a discordância. A resposta é uma categoria e há uma ordem entre essas categorias. Se essa variável é categórica, para descrevê-la devemos calcular as frequências absolutas (n) e relativas (%) de cada categoria.

Por outro lado, se estamos falando da escala Likert, ou seja, se estamos nos referindo à soma das pontuações de múltiplos itens Likert que se propõem a medir um mesmo constructo, aí temos em mãos uma variável que pode ser considerada numérica. Aqui, sim, podemos descrever a variável com medidas como média, mediana, desvio-padrão, quartis.
E já adiantando uma pergunta que pode estar passando pela sua cabeça: qual teste de hipóteses aplicar?
Se estamos falando de analisar um item Likert, usamos testes adequados a dados ordinais, como os testes não-paramétricos (Mann-Whitney, Kruskal-Wallis, etc).
Se queremos analisar uma escala Likert (ou seja, a soma das pontuações), podemos aplicar testes paramétricos, como teste-t e ANOVA, desde que os dados atendam aos pressupostos desses testes.
Ah, isso é um consenso? Claro que não, né? Já viu algo ser consenso em estatística? Mas é uma das recomendações mais comuns (Batterton; Hale, 2017).
O que define um item Likert? E o que seria um item tipo-Likert?
Item Likert
Bom, essa é uma definição que nunca esteve muito clara para mim. Mas um dos textos mais didáticos que eu li sobre isso foi “Likert Scales: Dispelling the Confusion”, do John S. Uebersax (link para o texto completo).
Um item Likert deve ter as seguintes características:
- As possibilidades de resposta estão organizadas horizontalmente
- As possibilidades de resposta são representadas por números inteiros consecutivos
- As possibilidades de resposta são representadas por rótulos verbais que indicam gradações espaçadas de forma aproximadamente uniforme
- Os rótulos verbais são bivalentes e simétricos em relação a um rótulo central neutro
Perceba que o item abaixo se encaixa em todos esses critérios. 1) Suas respostas estão organizadas na horizontal; 2) As possibilidades de resposta são representadas por números inteiros consecutivos, no caso, 1 a 5; 3) As possibilidades de resposta são representadas também por rótulos verbais (“concordo fortemente”, “concordo”, etc.) que estão espaçados de forma aproximadamente uniforme; 4) os rótulos são simétricos em relação a um rótulo central neutro (“não concordo, nem discordo”) e são bivalentes (ou seja, expressam direções opostas em relação a esse ponto neutro – de um lado temos “concordo fortemente”, do outro, “discordo fortemente”).
A escala Likert seria, portanto, uma escala composta por itens Likert.
Item tipo-Likert
Caso o item atenda a todos os pontos acima exceto o ponto 4, podemos chamá-lo de item tipo-Likert (em inglês, Likert-type item).
Ou seja, seria um item Likert aquele que atende aos pontos 1 a 3, mas:
- Apresenta uma quantidade par de respostas (isso é, sem não tem um neutro central)
- Não tem dois polos opostos (ou seja, não é bivalente)
O item abaixo não é bivalente, não podemos dizer que “Nunca” é o exato oposto de “Muito frequentemente”. Mas ainda assim o item atende aos critérios 1 a 3 e traz categorias espaçadas de forma aproximadamente uniforme:

Por outro lado, podemos ter um item com uma quantidade par de respostas, ou seja, sem um neutro central. Veja que, apesar de ter da quantidade par de respostas, o item abaixo atende aos critérios 1 a 3 e traz categorias espaçadas de forma aproximadamente uniforme:

Uma escala composta por itens tipo-Likert é, portanto, uma escala tipo-Likert (em inglês, Likert-type scale).
Escala visual analógica discreta
E se os meus itens não atenderem aos critérios 1 a 3? Aí a recomendação é tratá-los como variáveis categóricas ordinais, mas não como itens Likert ou tipo-Likert. O nome mais genérico que pode ser aplicado é “escala visual analógica discreta” (que vou abreviar como EVAD, uma tradução do inglês: discrete visual analog scales).
É o caso do item abaixo, que não atende ao critério 3:

Ou ainda desse item, que não atende aos critérios 2 ou 3:

Como representar os resultados de itens Likert (ou tipo-Likert ou EVAD)?
Como discutimos acima, os itens Likert (ou tipo-Likert ou EVAD) são variáveis categóricas ordinais. Portanto, utilizamos frequências absolutas (n) e relativas (%) para descrever esses resultados.
Representando os dados em tabela
Vamos usar como exemplo uma base de dados (adaptada do Kaggle) que avalia a satisfação com a empresa. A escala tem 13 questões, mas vamos focar em apenas 3. Veja como podemos descrever esses resultados em tabela, indicando a quantidade de funcionários (n) e quantos porcento deles (%) deu determinada resposta:
Questão | Resposta | n | % |
|---|---|---|---|
As mudanças são bem administradas na minha empresa | Discordo fortemente | 1.046 | 27,2 |
Discordo | 505 | 13,1 | |
Não concordo nem discordo | 351 | 9,1 | |
Concordo | 774 | 20,2 | |
Concordo fortemente | 1.165 | 30,3 | |
Os líderes da minha empresa fornecem uma liderança eficaz | Discordo fortemente | 905 | 23,7 |
Discordo | 386 | 10,1 | |
Não concordo nem discordo | 417 | 10,9 | |
Concordo | 676 | 17,7 | |
Concordo fortemente | 1.431 | 37,5 | |
Sinto que, em geral, minha empresa é bem gerenciada | Discordo fortemente | 861 | 22,3 |
Discordo | 380 | 9,9 | |
Não concordo nem discordo | 335 | 8,7 | |
Concordo | 720 | 18,7 | |
Concordo fortemente | 1.557 | 40,4 |
Representando os dados em gráfico
Ok, mas e graficamente? Como podemos representar esses resultados?
Vou te apresentar um gráfico que eu amo – e que por muitos anos eu não soube que existia: o gráfico de barras divergentes (em inglês, diverging bar plot). Aqui vou recomendar o excelente artigo de Robbins; Heiberger et al. (2011) que discute as possibilidades de representação de itens Likert e conclui que o gráfico de barras divergentes é a ferramenta mais apropriada (acesse o PDF aqui).
O que seria um gráfico de barras divergentes?
Bom, um gráfico de barras divergentes é semelhante a um gráfico de barras empilhadas, em que as frequências – em geral, as relativas (%) – de todas as categorias são empilhadas de forma que uma barra representa o total.
Se quiséssemos criar um gráfico de barras empilhadas com as frequências relativas das respostas às três questões acima, ele ficaria assim:
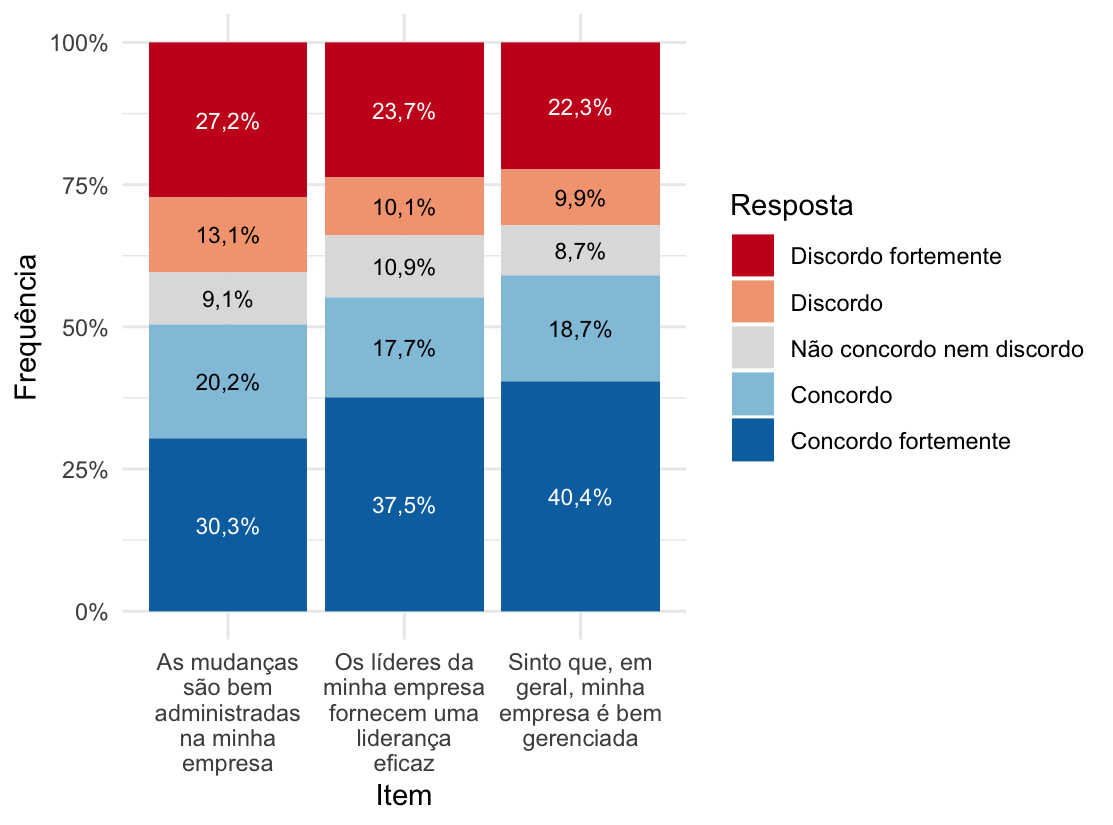
Perceba como as porcentagens batem com as calculadas na tabela e como a soma de todas as porcentagens de uma mesma barra dá 100%. Veja também como eu atribui cores que estão normalmente associadas a concordo (algo “positivo”, azul) e discordo (algo “negativo”, vermelho). E perceba também que nesse caso o “concordo” indica de fato uma opinião positiva em relação à empresa.
Podemos melhorar um pouco esse gráfico. Uma excelente possibilidade é deixar as afirmações no eixo y e a porcentagem no eixo x. Dessa forma, facilitamos a leitura. Vou também colocar a legenda com as cores na parte inferior do gráfico, para ela pegar menos espaço, e vou deixar o eixo y sem título (afinal, é meio óbvio que ele traz os itens):
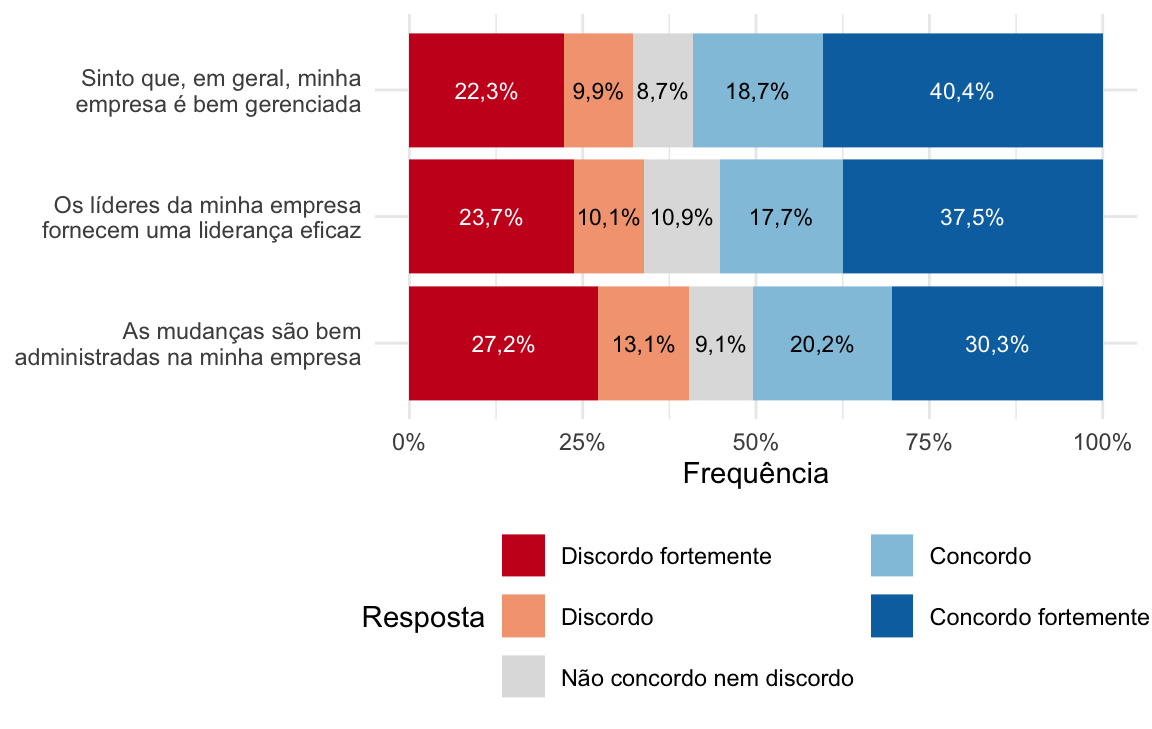
Como tornar a informação ainda mais visível? Geralmente quando trabalhamos com itens Likert (ou tipo-Likert) estamos interessados em avaliar a proporção de concordâncias (sejam fortes ou não) e discordâncias (fortes ou não). É para facilitar essa visualização que entra a parte “divergente” do gráfico de barras sugerido para esses itens.
O gráfico de barras divergentes centraliza a resposta neutra, deixando discordâncias de um lado (no nosso caso, ficarão à esquerda) e concordâncias do outro (aqui, à direita). Além disso, ele nos mostra a soma das porcentagens das categorias de discordância (à esquerda) e concordância (à direita). No centro, vemos a porcentagem da categoria neutra. Veja como isso facilita identificarmos as questões com maiores e menores proporções de concordância (seja forte ou não):
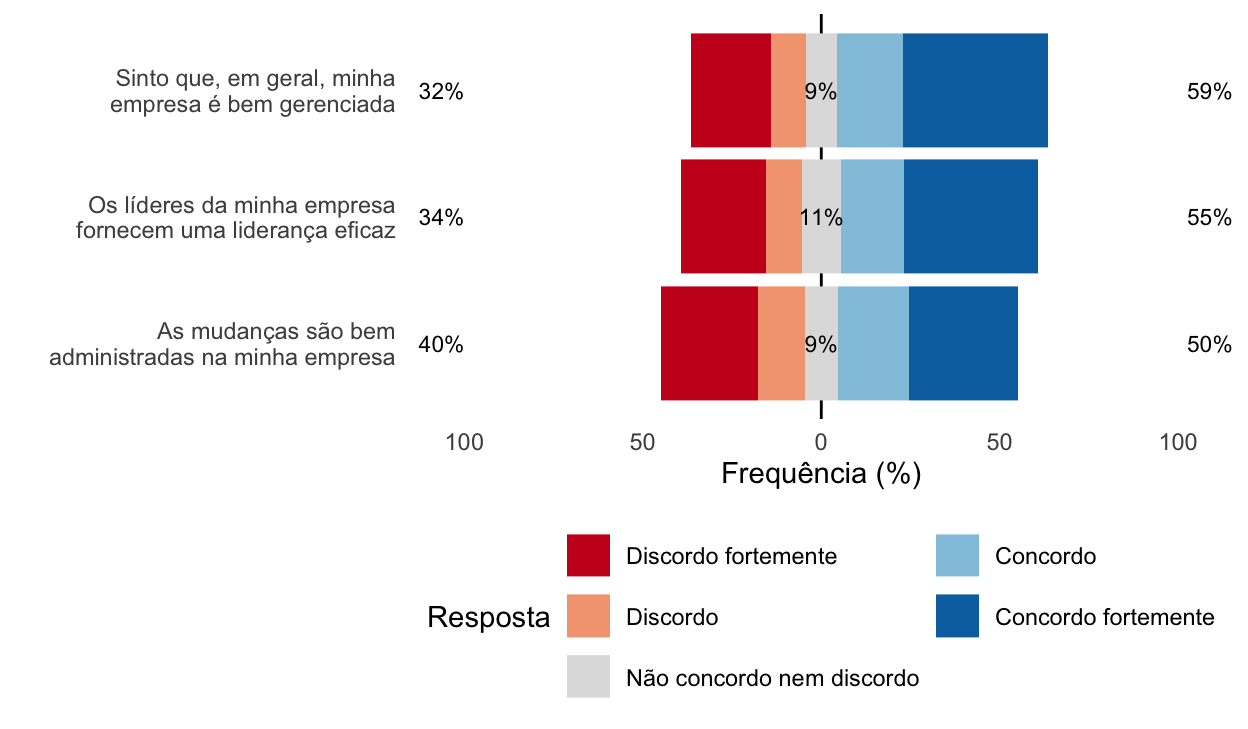
Esse é o famoso gráfico de barras divergentes recomendado por Robbins; Heiberger et al. (2011).
Tá, mas como eu construo esse gráfico?
Eu construí o gráfico acima em R. Já vi vídeos ensinando a construir esse gráfico em Excel, com base em algumas gambiarras. Mas, honestamente? Me parece muito mais trabalhoso ir pelo caminho Excel + gambiarras do que aprender o pouco necessário para construir esse gráfico no R.
Se você prefere assistir a tutoriais em vídeo, recomendo esse vídeo do meu canal, em que eu explico passo-a-passo como construir esse gráfico no R. No canal você também encontra vídeos ensinando a instalar o R e a dar os seus primeiros passos com ele.
Não tem tempo para aprender a fazer esse gráfico, mas precisa construí-lo? Eu ofereço um serviço de análise de dados em que você pode me contratar para realizar as análises descritivas dos seus itens Likert. O contato é via formulário que está nesta página.
Para construir esse gráfico, vamos inicialmente ler a base de dados. Você a encontra disponível para download aqui.
# Instalando e carregando os pacotes que serão utilizados
if(!require(pacman)){install.packages("pacman")}## Loading required package: pacmanpacman::p_load(tidyverse, readxl, likert, RColorBrewer)
# Lendo a base de dados
dados <- readxl::read_xlsx("Banco_Likert.xlsx")
# Visualizando as primeiras 10 linhas dessa base
head(dados, n = 10)## # A tibble: 10 × 14
## Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 1 1 2 3 4 4 3 5 4 4 4 3
## 2 5 5 5 5 5 5 5 5 5 5 5 5 5
## 3 1 2 1 3 2 3 5 2 1 1 1 1 1
## 4 1 1 1 1 1 1 1 1 1 1 1 1 1
## 5 1 1 1 3 3 3 4 3 1 2 1 1 1
## 6 4 5 5 5 3 5 4 5 5 4 4 5 5
## 7 5 5 5 5 5 5 5 5 5 5 5 5 5
## 8 4 2 4 4 1 4 4 3 3 3 3 3 2
## 9 5 4 5 4 NA 5 NA 4 5 5 5 5 5
## 10 4 4 3 4 3 5 5 4 3 4 4 4 4
## # ℹ 1 more variable: `Tamanho da empresa` <chr>Veja que na base as respostas estão representadas por números. Mas esses números significam o grau de concordância. Portanto, antes de construirmos o gráfico, vamos renomear as categorias desses itens Likert:
# Atribuindo os rótulos (discordo, concordo) às questões 1 a 13
dados[,1:13] <- lapply(dados[,1:13], factor, levels = 1:5,
labels = c("Discordo fortemente", "Discordo",
"Não concordo nem discordo",
"Concordo", "Concordo fortemente"),
ordered = T)
# Visualizando as primeiras 10 linhas dessa base
head(dados, n = 10)## # A tibble: 10 × 14
## Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13
## <ord> <ord> <ord> <ord> <ord> <ord> <ord> <ord> <ord> <ord> <ord> <ord> <ord>
## 1 Disc… Disc… Disc… Disc… Não … Conc… Conc… Não … Conc… Conc… Conc… Conc… Não …
## 2 Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc…
## 3 Disc… Disc… Disc… Não … Disc… Não … Conc… Disc… Disc… Disc… Disc… Disc… Disc…
## 4 Disc… Disc… Disc… Disc… Disc… Disc… Disc… Disc… Disc… Disc… Disc… Disc… Disc…
## 5 Disc… Disc… Disc… Não … Não … Não … Conc… Não … Disc… Disc… Disc… Disc… Disc…
## 6 Conc… Conc… Conc… Conc… Não … Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc…
## 7 Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc… Conc…
## 8 Conc… Disc… Conc… Conc… Disc… Conc… Conc… Não … Não … Não … Não … Não … Disc…
## 9 Conc… Conc… Conc… Conc… <NA> Conc… <NA> Conc… Conc… Conc… Conc… Conc… Conc…
## 10 Conc… Conc… Não … Conc… Não … Conc… Conc… Conc… Não … Conc… Conc… Conc… Conc…
## # ℹ 1 more variable: `Tamanho da empresa` <chr>Agora que os rótulos estão adequados e estabelecemos que esses itens são variáveis categóricas (factor) ordinais (ordered = T), podemos montar o nosso gráfico. Vamos, para isso, utilizar duas funções do pacote likert:
# Criando a base de dados no formato adequado para construção do gráfico
# Para isso, usamos a função "likert" do pacote "likert"
# Veja que selecionamos as colunas 1 a 13 (dados[1:13])
dados_graf <- likert::likert(as.data.frame(dados[1:13]))
# Para criar o gráfico, basta usarmos a função likert.bar.plot, também do pacote likert
likert::likert.bar.plot(dados_graf)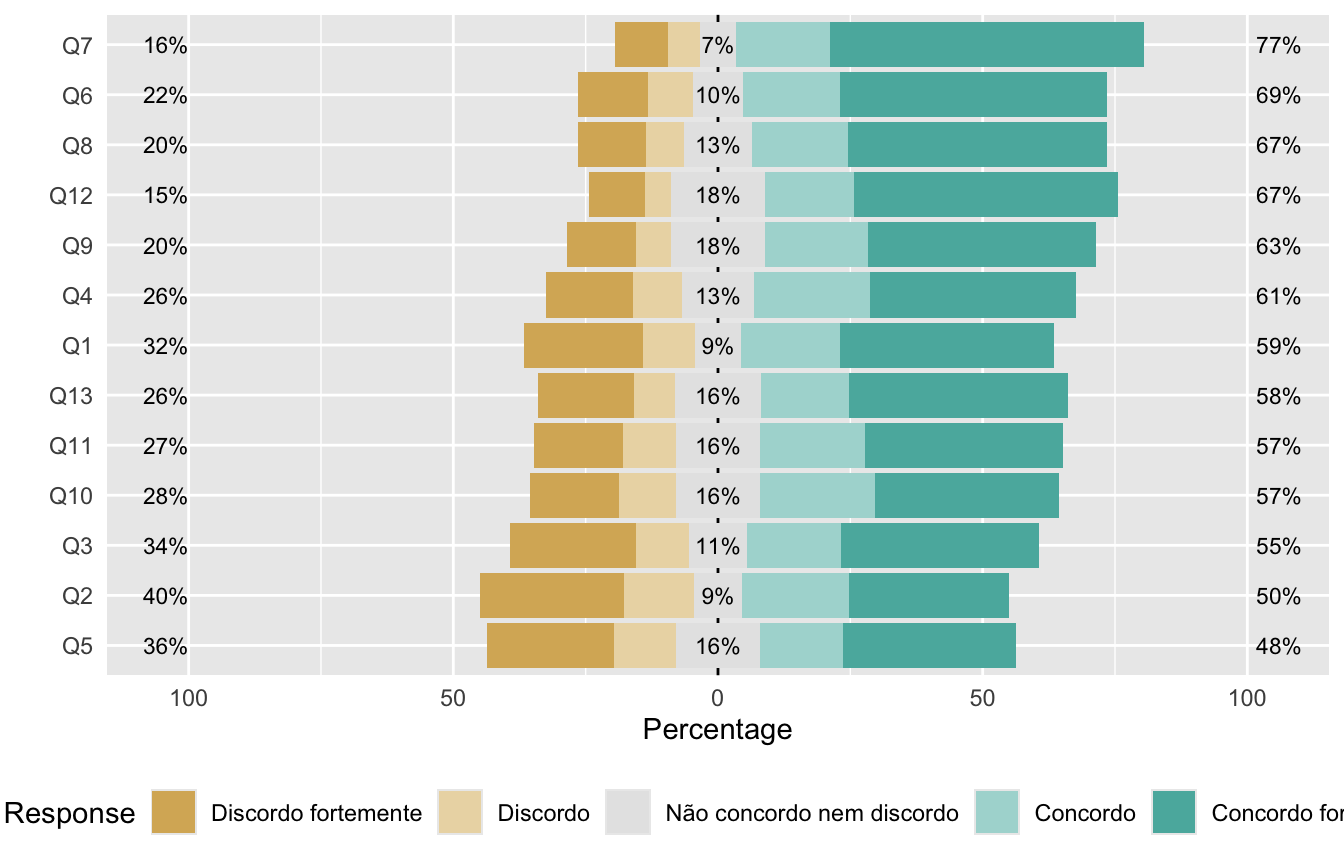
O gráfico está criado! Tudo que vamos modificar a partir daqui são detalhes estéticos. O pacote likert constroi esse gráfico com o pacote ggplot2 (que carregamos quando carregamos o tidyverse lá no começo). Por isso, podemos fazer todos os ajustes estéticos utilizando funções do ggplot2.
O
ggplot2é meu pacote favorito do R, mas não é o pacote mais intuitivo do mundo. Eu tenho uma playlist no YouTube justamente ensinando o bê-a-bá doggplot2. Recomendo fortemente caso você tenha aí o sonho de ser fluente nesse pacote!
Bom, o primeiro passo aqui será tirar esse fundo cinza (que eu odeio). Para isso, basta adicionarmos um tema que não tenha fundo cinza, como o theme_minimal(). Perceba que esse tema também modifica a posição da legenda, deixando-a à direita do gráfico, não mais na parte inferior.
Vou também já alterar as palavras em inglês (afinal, estamos construindo um gráfico em português). Para trocar o “Percentage” por “Frequência (%)” vamos adicionar uma camada labs() e trocar o rótulo do eixo y. E, sim, é bem contraintuitivo alterar o eixo y, sendo que “Percentage” está no eixo x, mas internamente o pacote likert constroi a porcentagem no eixo y e depois inverte os eixos. Portanto, é assim que conseguimos modificar o texto.
Para trocar “Response” por “Resposta”, a solução é um pouco menos óbvia. Precisamos adicionar uma camada guides() e trocar o título do preenchimento (fill).
likert::likert.bar.plot(dados_graf) +
guides(fill = guide_legend(title = "Resposta")) +
labs(y = "Frequência (%)") +
theme_minimal()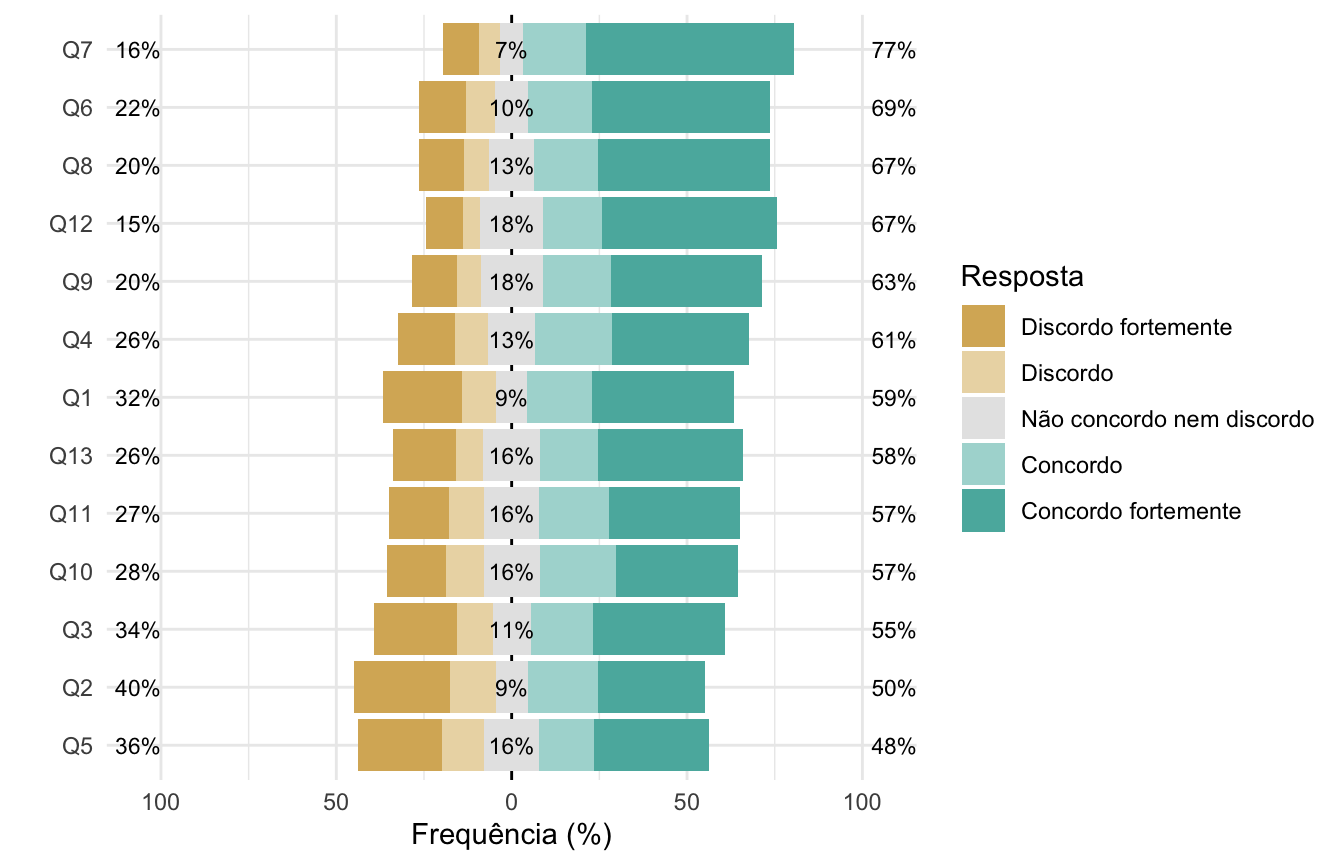
Já está um gráfico bem decente, vai? E com pouquíssimas linhas de código!
Por fim, vou mudar as cores para deixar as concordâncias em tons de azul e as discordâncias em tons de vermelho. Para isso, vou usar uma paleta chamada “RdBu” (de Red Blue) do pacote RColorBrewer. Vou pedir por 5 cores e vou alterar a do centro (a terceira cor) para ser um cinza claro, porque eu acho o padrão da paleta muito branco. Para adicionar a nova paleta ao gráfico, adicionamos uma camada scale_fill_manual():
paleta <- RColorBrewer::brewer.pal(n = 5, name = "RdBu")
paleta[3] <- "#DFDFDF"
likert::likert.bar.plot(dados_graf) +
guides(fill = guide_legend(title = "Resposta")) +
labs(y = "Frequência (%)") +
scale_fill_manual(values = paleta) +
theme_minimal()## Scale for fill is already present.
## Adding another scale for fill, which will replace the existing scale.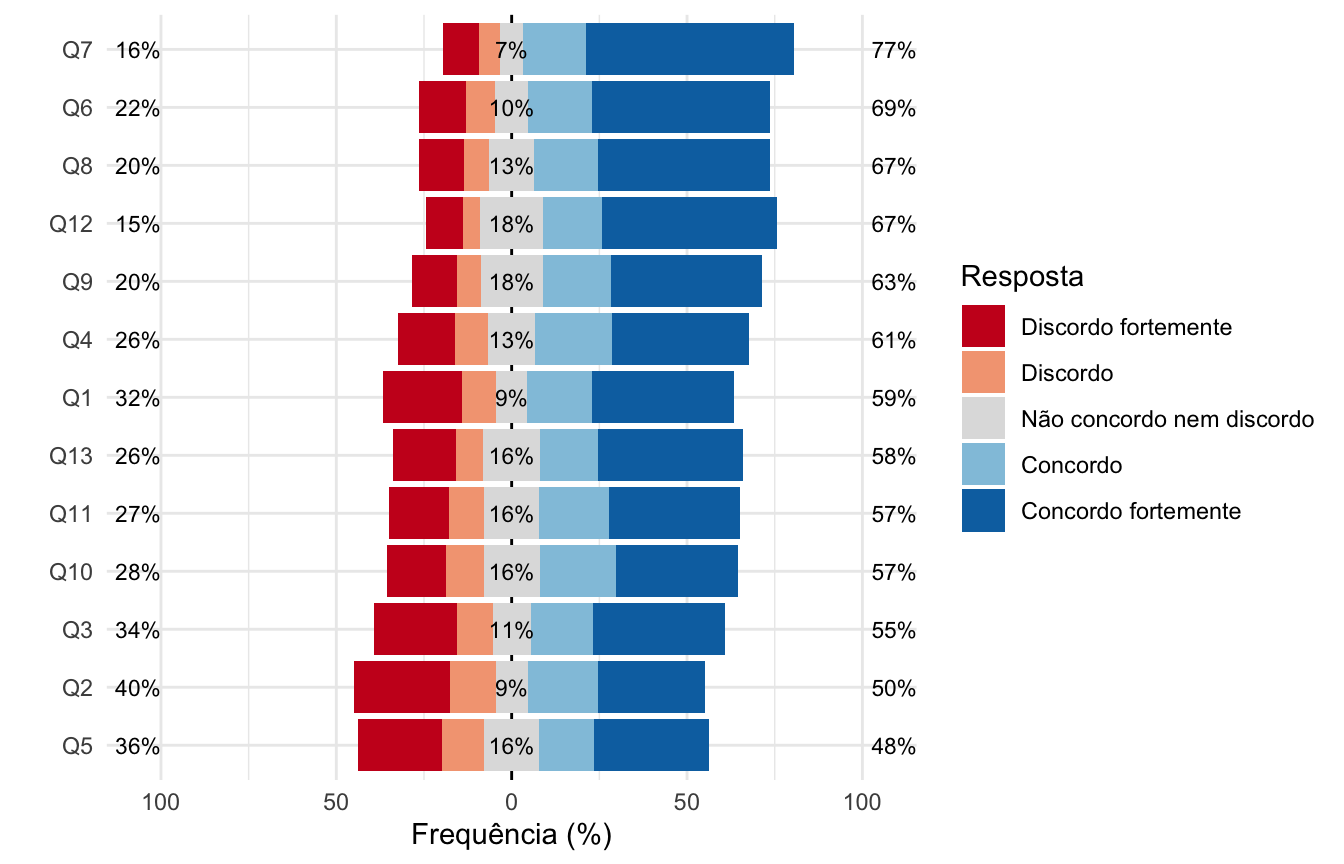
E prontinho! 🎉
Veja que, por padrão, a função likert.bar.plot ordena os itens da maior para a menor concordância. Caso queira deixá-los na ordem do questionário, você pode adicionar o argumento group.order = colnames(dados)[1:13] a essa função:
paleta <- RColorBrewer::brewer.pal(n = 5, name = "RdBu")
paleta[3] <- "#DFDFDF"
likert::likert.bar.plot(dados_graf, group.order = colnames(dados)[1:13]) +
guides(fill = guide_legend(title = "Resposta")) +
labs(y = "Frequência (%)") +
scale_fill_manual(values = paleta) +
theme_minimal()## Scale for fill is already present.
## Adding another scale for fill, which will replace the existing scale.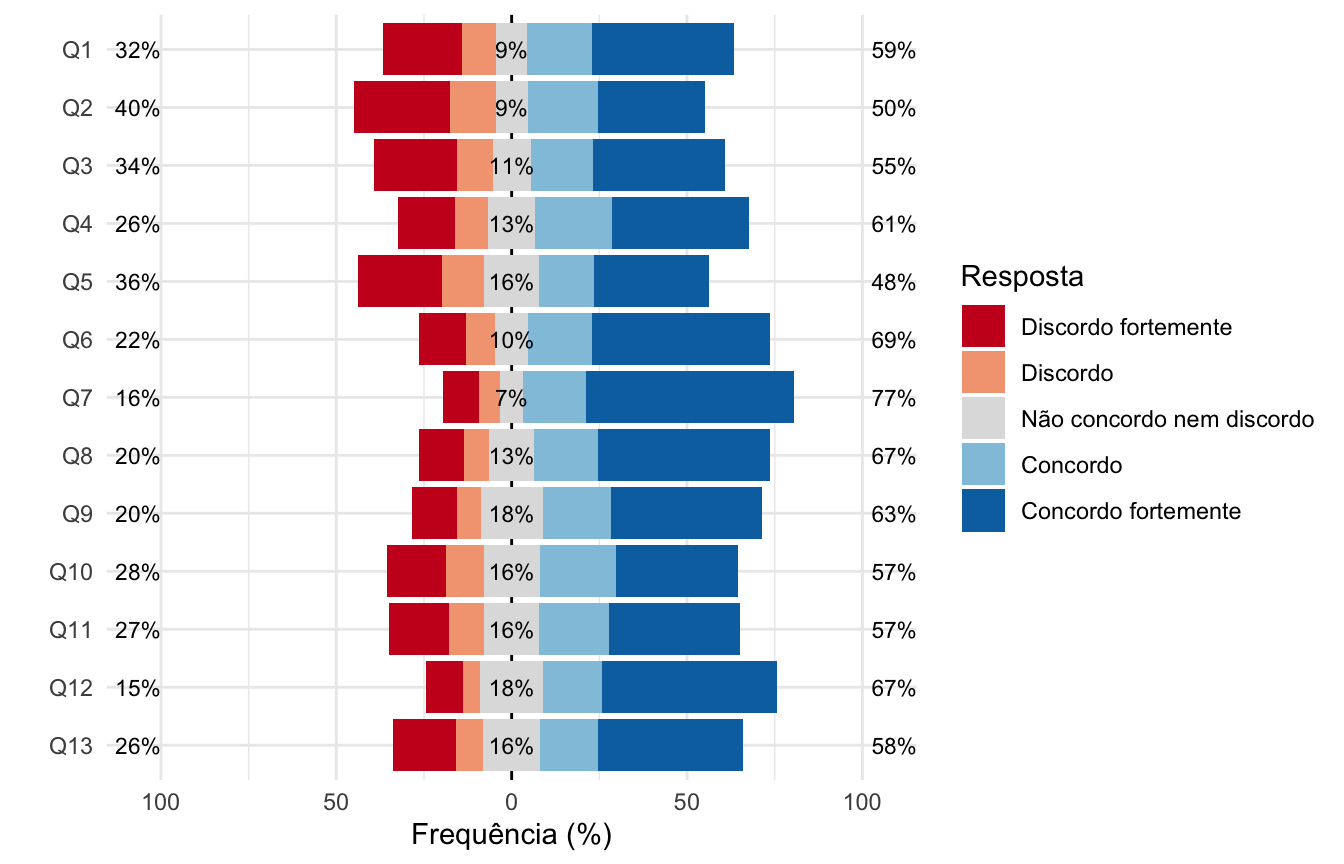
E aí, já conhecia esse gráfico? O post foi útil? Me conta nos comentários? Aproveito para reforçar a indicação: no vídeo do YouTube eu detalho ainda mais a construção desse gráfico e te explico também como construir um gráfico Likert com barras por grupo.
Como citar esse post, nas normas da ABNT
PERES, Fernanda F. Como representar dados em escala Likert?. Blog Fernanda Peres, São Paulo, 29 abr. 2025. Disponível em: https://fernandafperes.com.br/blog/graficos-likert/.
comments powered by Disqus